This dataset shows the spending, incentives, private investment, bill savings, and energy savings for all impacted middle income hh which received the assisted project incentives for WNY.
Explanation of variables: Overall spending: total cost of the project for all of WNY Overall incentives: the amount of money that the program gave to the project for all of WNY Overall private investment: equal to the difference between overall spending for all of WNY and overall incentive Overall bill savings: first year modeled energy bill savings for households in the program, versus their energy bill cost before the program for all of WNY Overall energy savings: estimated annual kwh savings in energy for all of WNY
In [1]:
# Load data_prep variables saved in previously run sessionlibrary(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(tigris)
To enable caching of data, set `options(tigris_use_cache = TRUE)`
in your R script or .Rprofile.
library(tidycensus)library(janitor)
Attaching package: 'janitor'
The following objects are masked from 'package:stats':
chisq.test, fisher.test
library(sf)
Linking to GEOS 3.11.1, GDAL 3.6.2, PROJ 9.1.1; sf_use_s2() is TRUE
options(tigris_use_cache =TRUE)library(scales)
Attaching package: 'scales'
The following object is masked from 'package:purrr':
discard
The following object is masked from 'package:readr':
col_factor
Underlying assumptions to be added: 1. We are assuming that one project is equal to one household. This is because we do not have direct HH information from the assisted dataset but since it is residential projects we have inferred that each project is a hh.
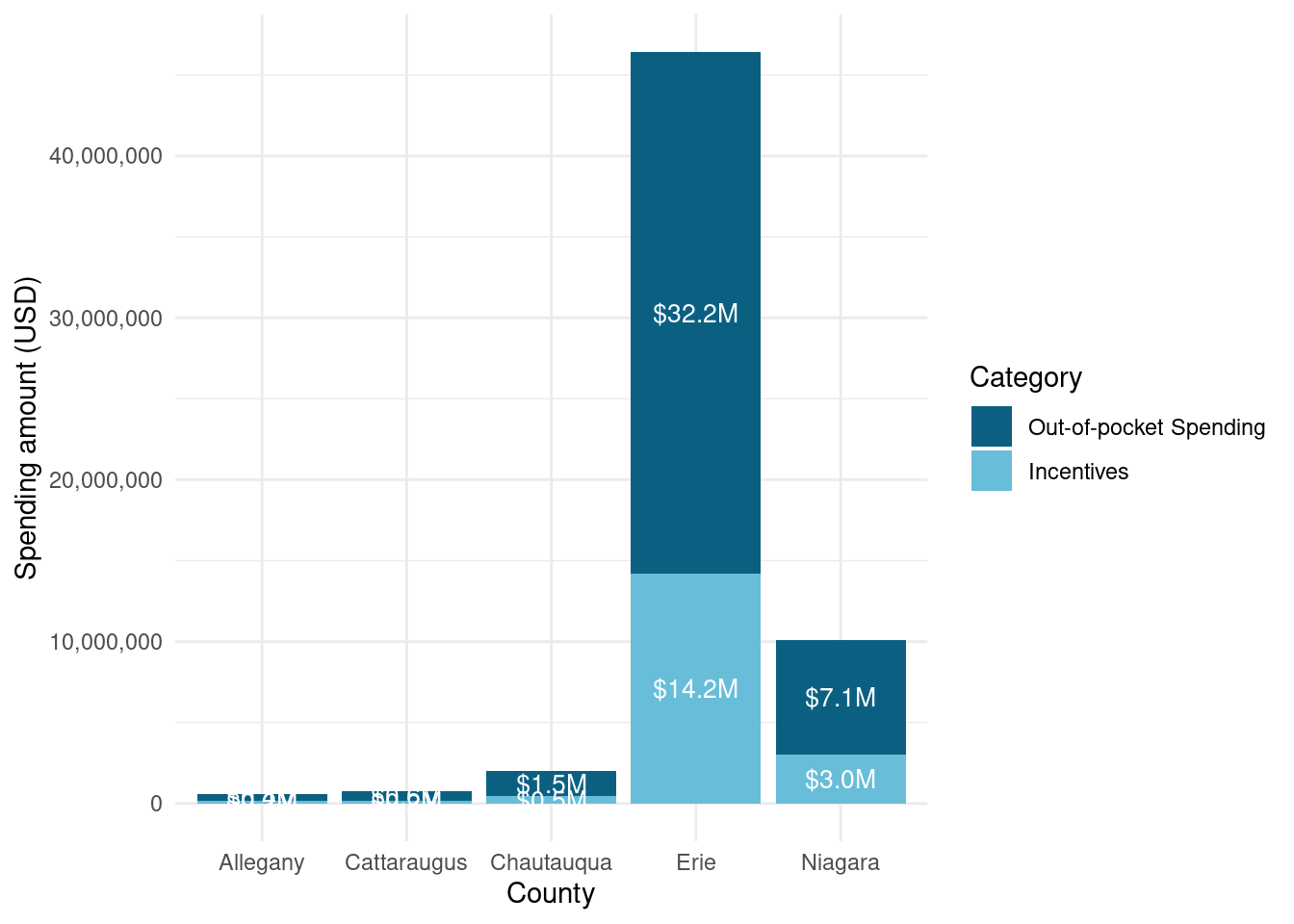
How much money was spent overall in WNY (via assisted incentives)? Answer: $ 18,081,182
How much private investment did that catalyze? Answer: $ 41,853,095
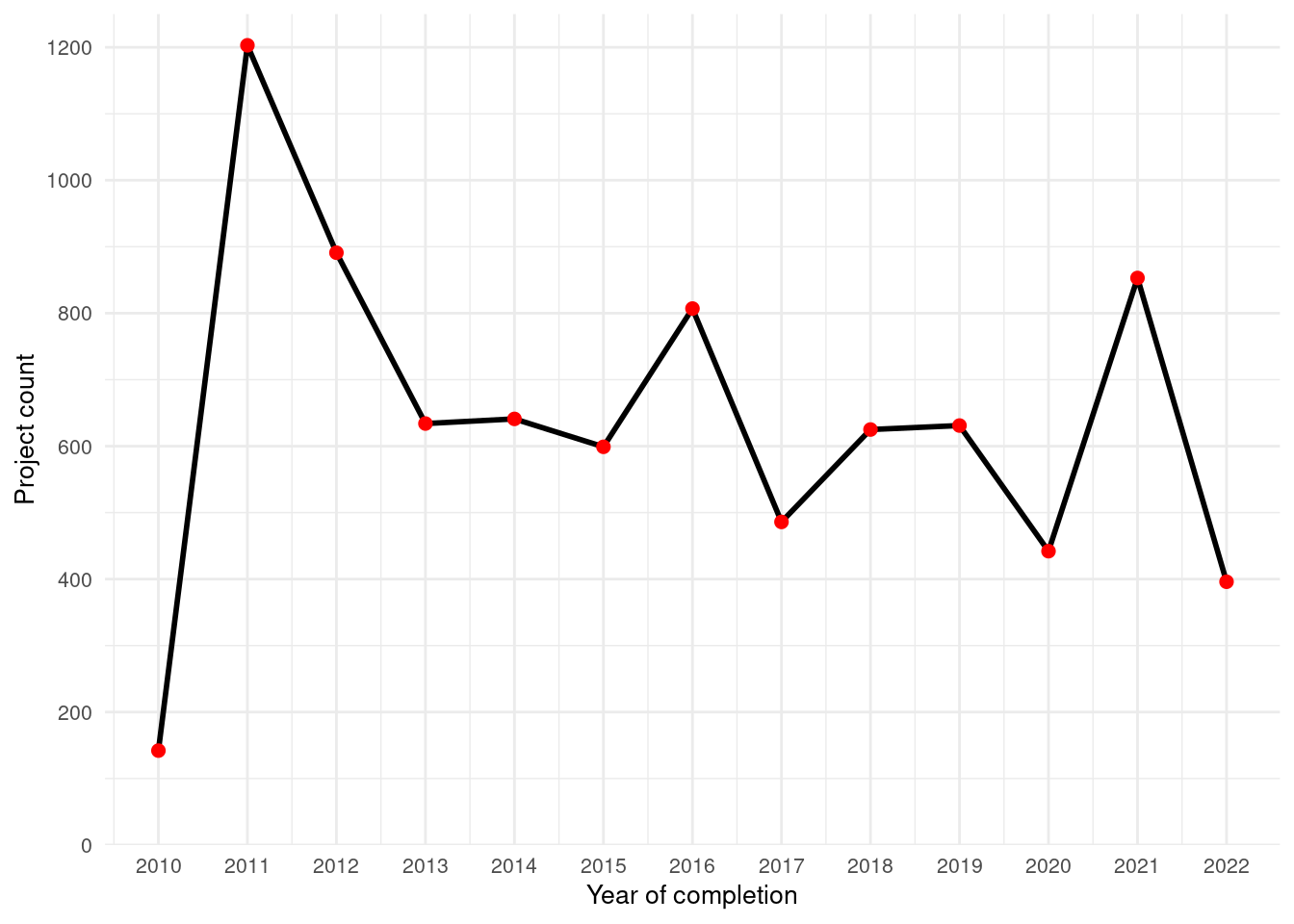
How many projects were completed over time?
Answer: Overall, 8,401 Assisted projects were completed in this time period.
See timeseries graph below
In [3]:
# Comments say last 2 years should be excluded but code includes 2022?region_projectcountbyyear_assisted_wny <- projects_assisted |>filter(county %in% wny_counties) |>mutate(completion_year =year(project_completion_date) ) |>1filter(!completion_year %in%c(2023)) |>summarise(project_count_by_year =n(),.by = completion_year )
1
The last two years are excluded because there have been fewer projects completed during this time (some might still be in process or started later).
Assisted program measures per beneficiary household by county
County
Total spending
Incentives
Out-of-pocket spending
Erie
$7,107
$2,175
$4,932
Niagara
$6,809
$2,041
$4,767
Cattaraugus
$9,160
$2,219
$6,941
Chautauqua
$8,578
$2,055
$6,523
Allegany
$9,660
$2,681
$6,978
Percent of beneficiaries that benefitted by county:
Allegany: 2.8782 %
Cattaraugus: 2.2615 %
Chautauqua: 3.8309 %
Erie: 14.0412%
Niagara: 13.745 %
Assisted appears to have reached a 4-5x larger share of the eligible population in Erie and Niagara counties than in the others. Therefore, the outsized spending on these counties does not solely reflect higher population density.
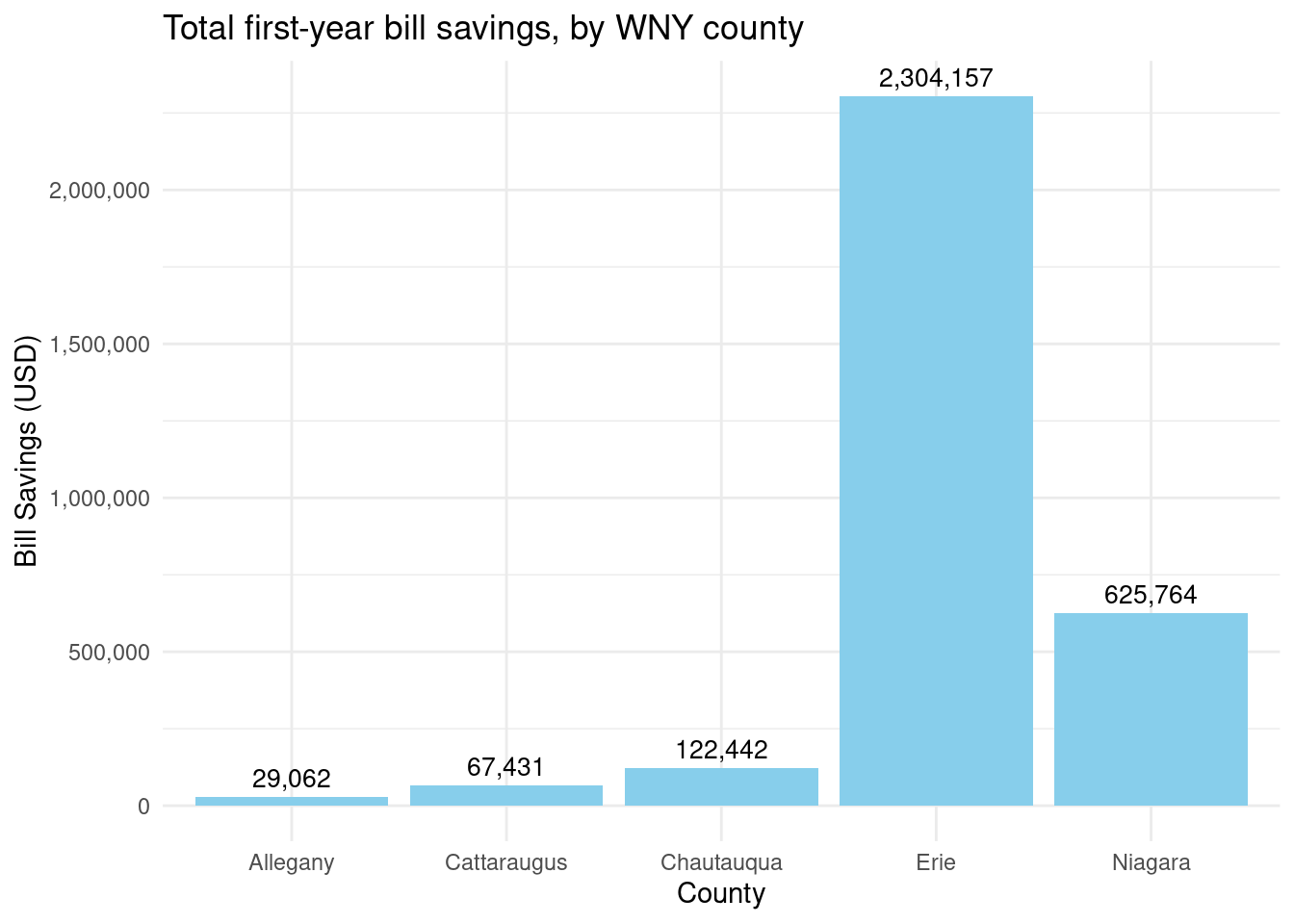
How many bill savings? Overall: 3,148,856
By county? - Allegany: 29,062 - Cattaraugus: 67,431 - Chautauqua: 122,442 - Erie: 2,304,157 - Niagara: 625,764
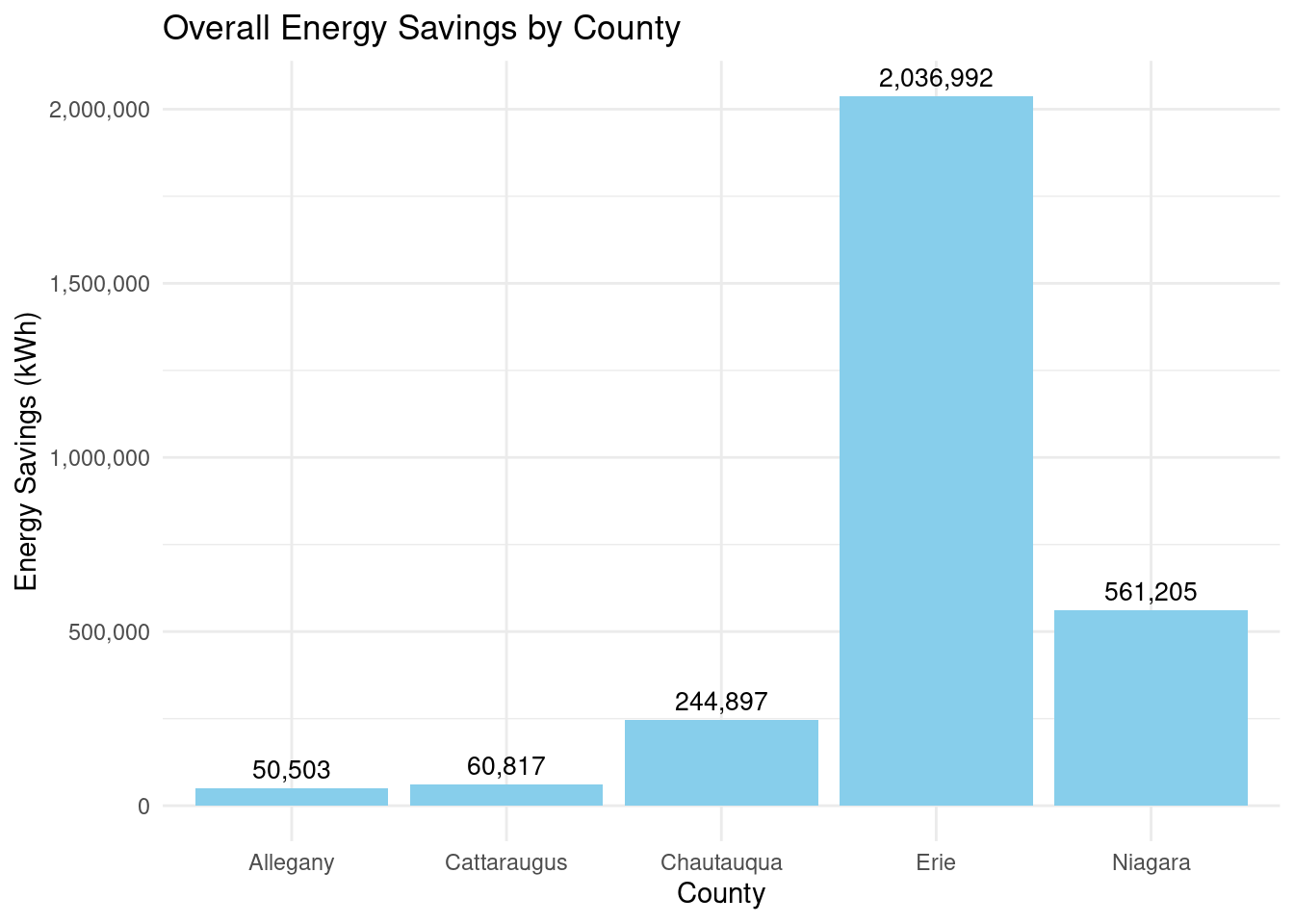
How many energy savings? Overall: 2,954,414 By county? - Allegany: 50,503 - Cattaraugus: 60,817 - Chautauqua: 24,4897 - Erie: 2,036,992 - Niagara: 561,205
Geography
The data frame zcta_hhmi_assisted_wny -> zcta_totalstats_assisted_wny is created to show both hh level income information and project level information. It is on the zcta level.
In this right join, every zip in zip_projectstats_assisted_wny should find a zcta match in zcta_hhlmi_wny. Our final df should have 139 rows as in zip_projectstats_assisted_wny, which it does so we can proceed.
The df zcta_totalstats_bybeneficiary_assisted_wny is created to get total spending/saving numbers and to get spending/savings by assisted beneficiary.
It is expected that not all rows of zcta_boundary_wny will find a match, because there are some PO boxes/some ZCTAs that are not in the assisted project data. As long as our final df has the same number of zctas as zcta_totalstats_assisted_wny, we are fine - which it does.
We are making this a spatial data frame so that we can use ggplot to make the maps.
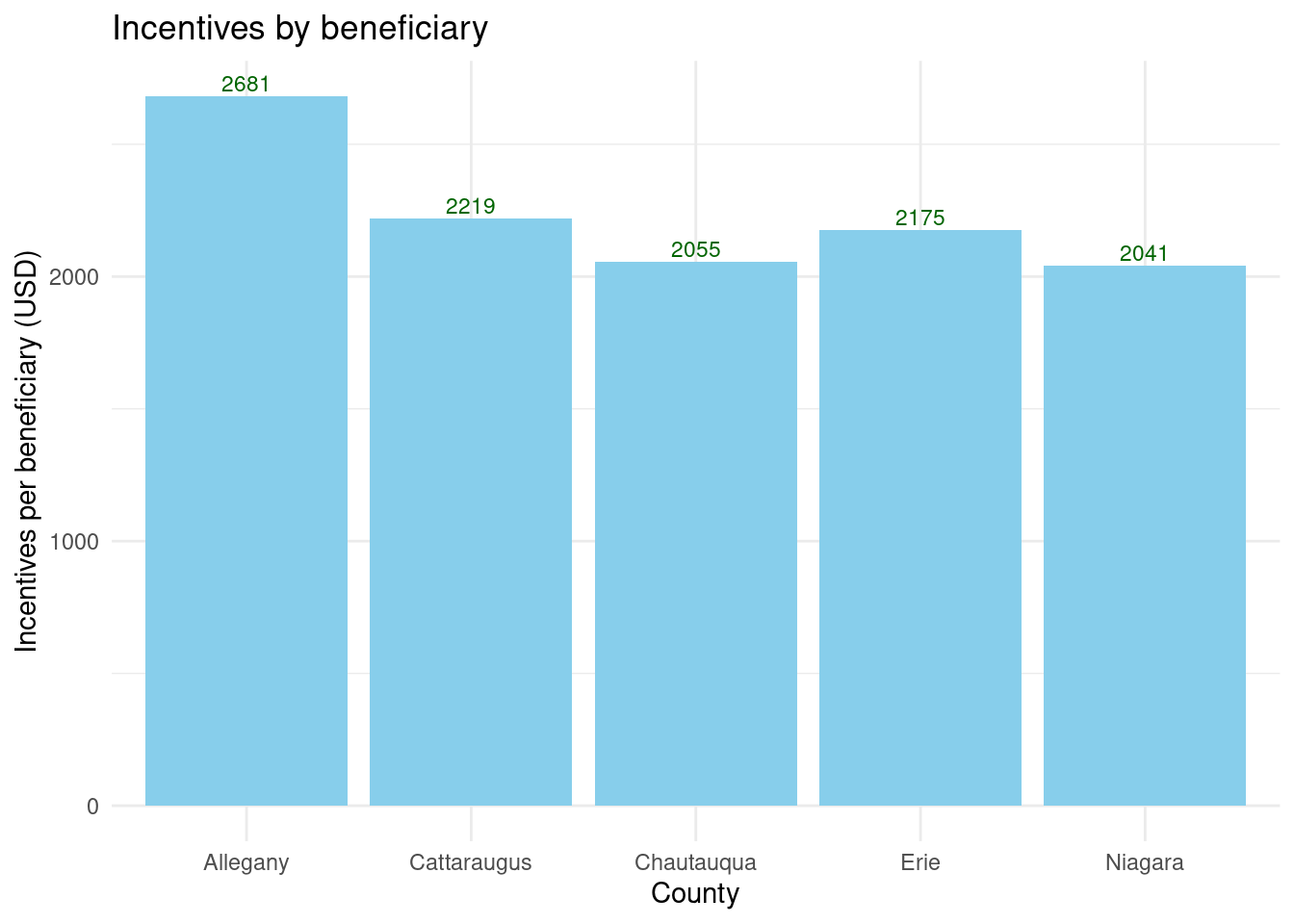
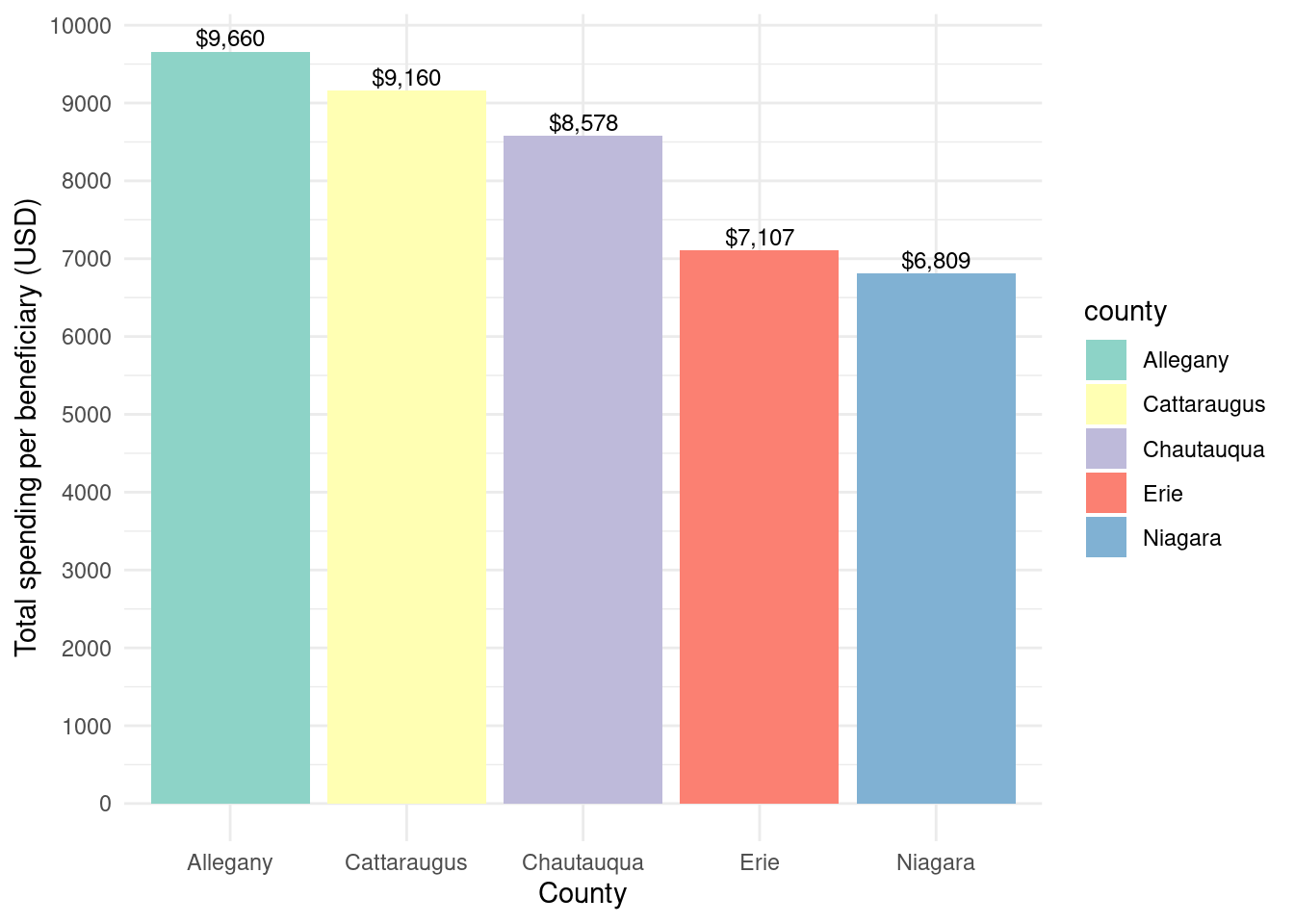
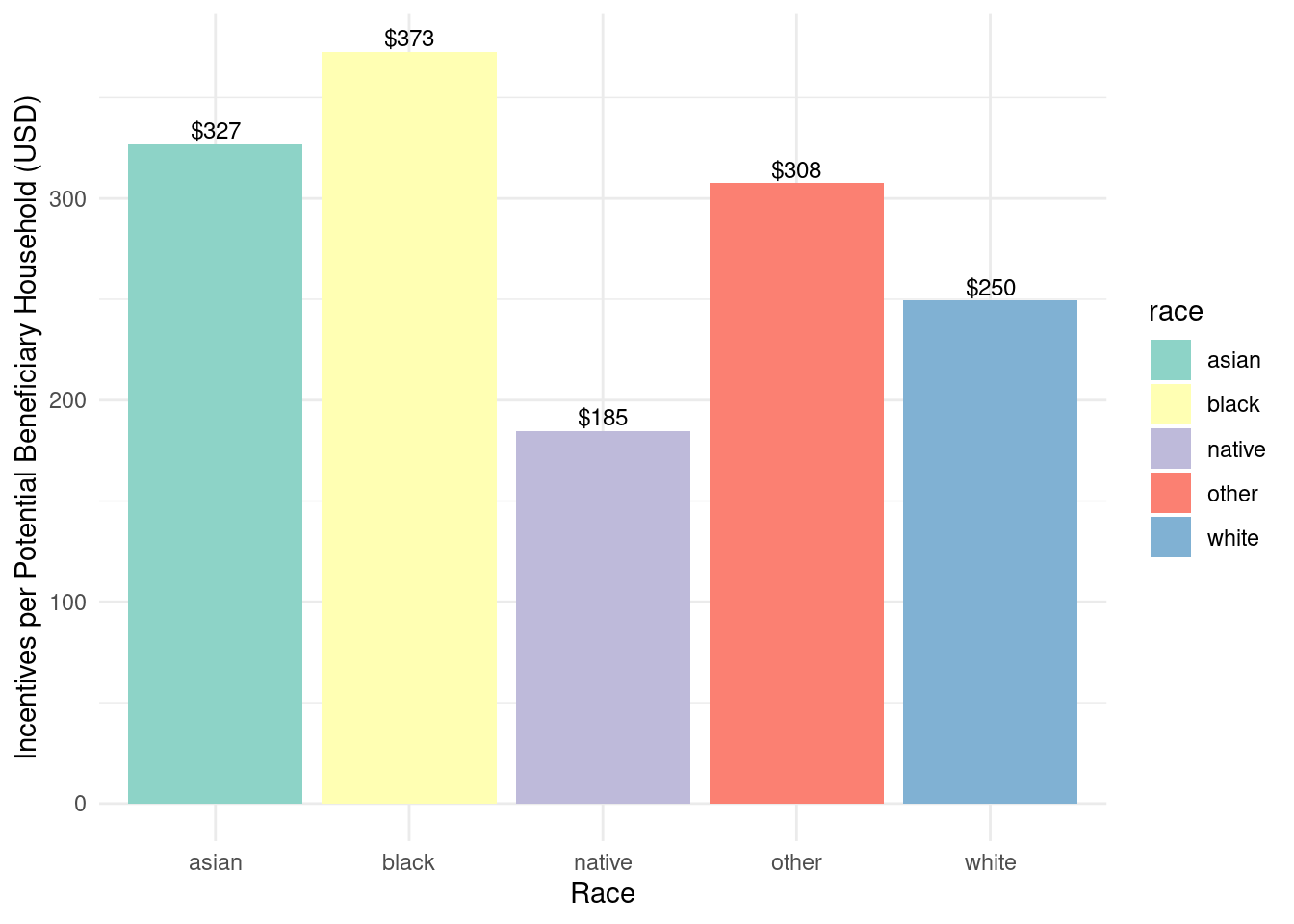
Allegany had the highest incentive dollar amount per beneficiary, while other counties were fairly similar in terms of amount.
Graph showing spending by beneficiary per county:
In [29]:
county_beneficiaries_assisted_wny |>ggplot(aes(x = county, y = incentives_by_beneficiary)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label =round(incentives_by_beneficiary)), vjust =-0.3, color ="darkgreen", size =3 ) +labs(title ="Incentives by beneficiary", x ="County", y ="Incentives per beneficiary (USD)" ) +theme_minimal()
The average Assisted incentive was pretty comparable across counties, $2K and $2.2K. Allegany had a higher average, $2681, but this is largely an artifact of the very few projects that have take place there, less than 1% of the spending.
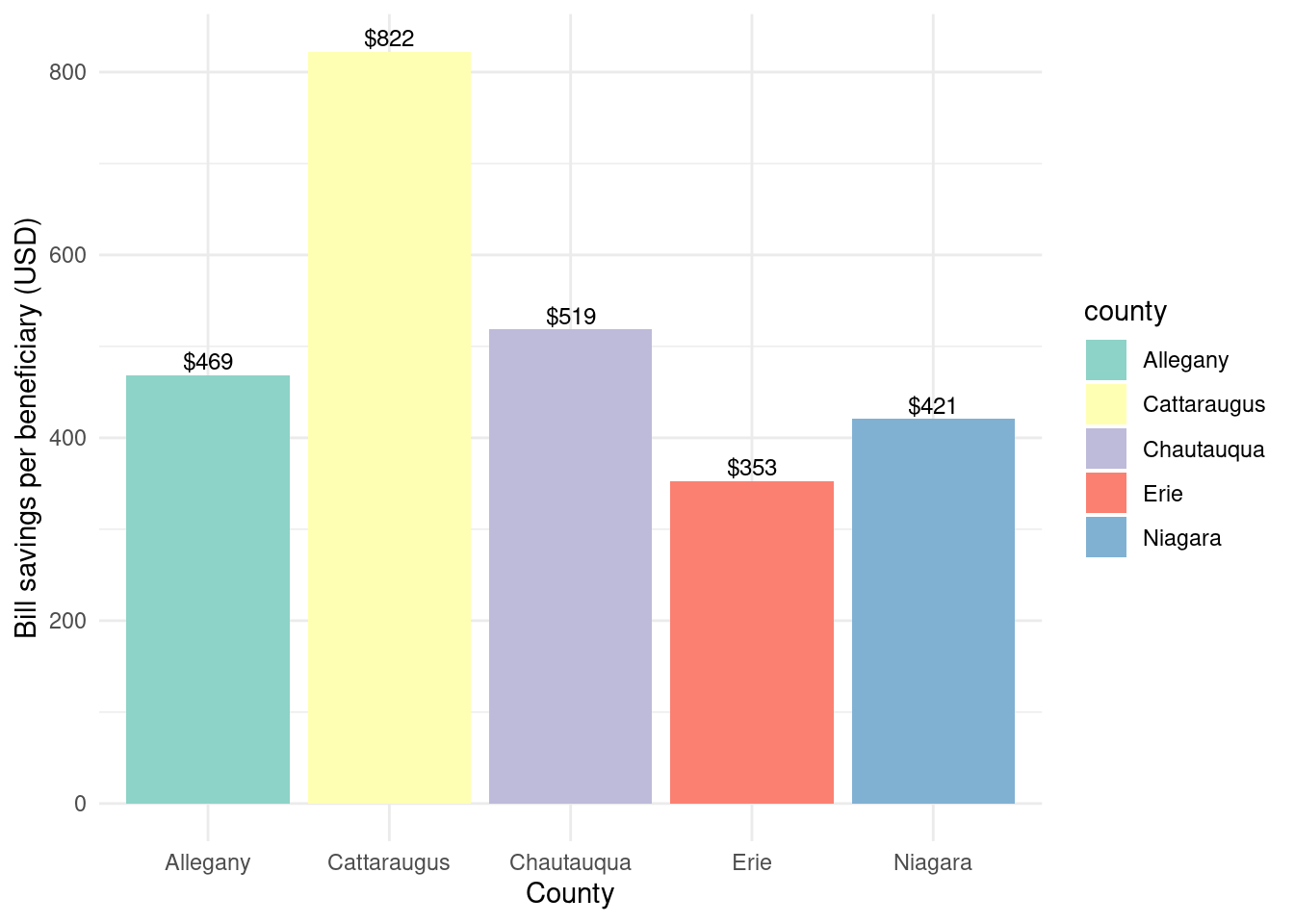
Graph showing bill savings by beneficiary per county:
In [30]:
county_beneficiaries_assisted_wny |>ggplot(aes(x = county, y = billsavings_by_beneficiary)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label =round(billsavings_by_beneficiary)), vjust =-0.3, color ="blue", size =3 ) +labs(title ="Bill savings by beneficiary", x ="County", y ="Bill savings per beneficiary (USD)" ) +theme_minimal()
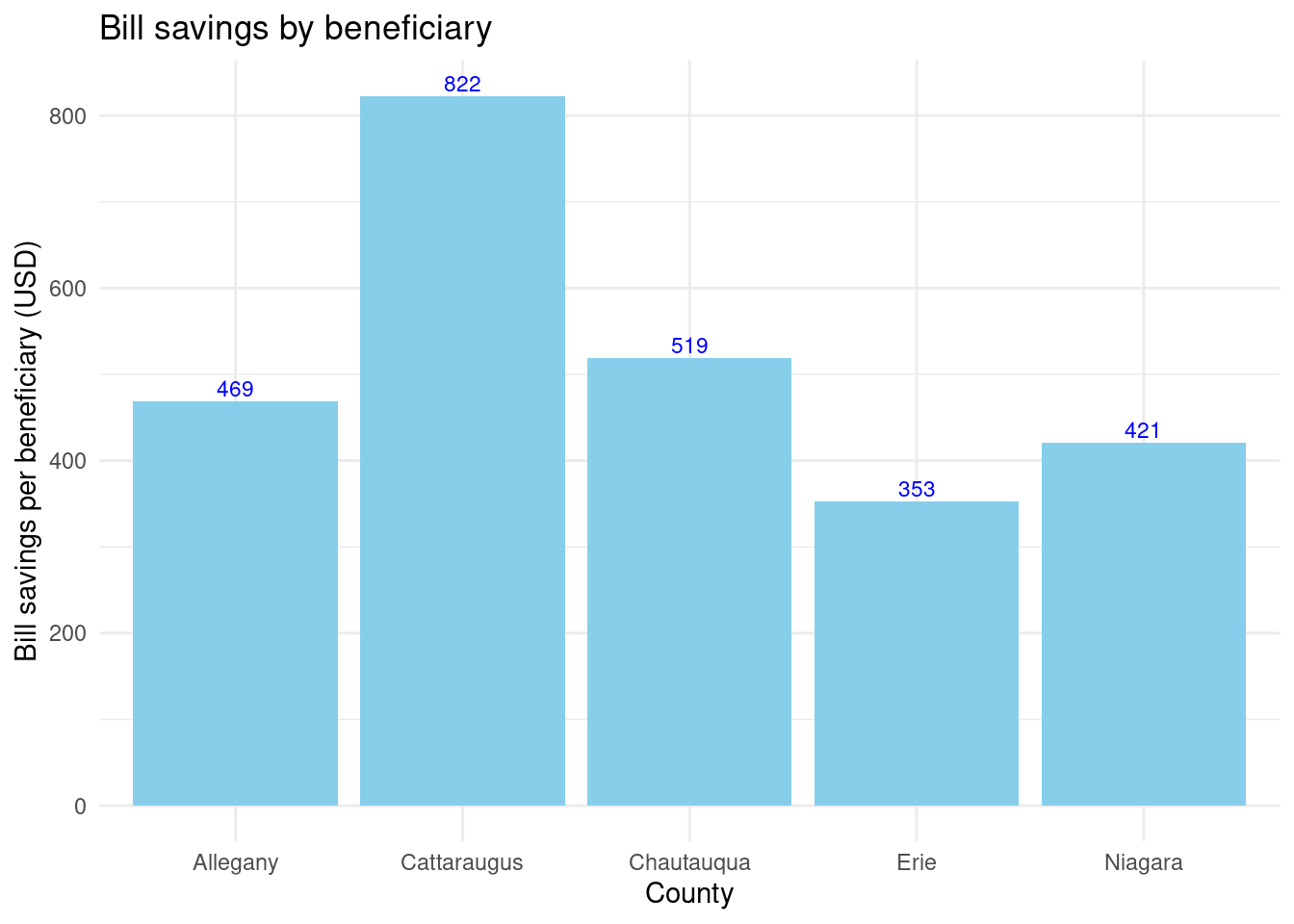
There’s more variation in first-year bill savings… rural counties seem to have higher savings on average.
According to the National Agricultural and Rural Development Policy Center (NARDeP), “residential per household energy consumption in rural areas is about 10% higher compard to urban areas.” Could be worth seeing if that is what is happening here?
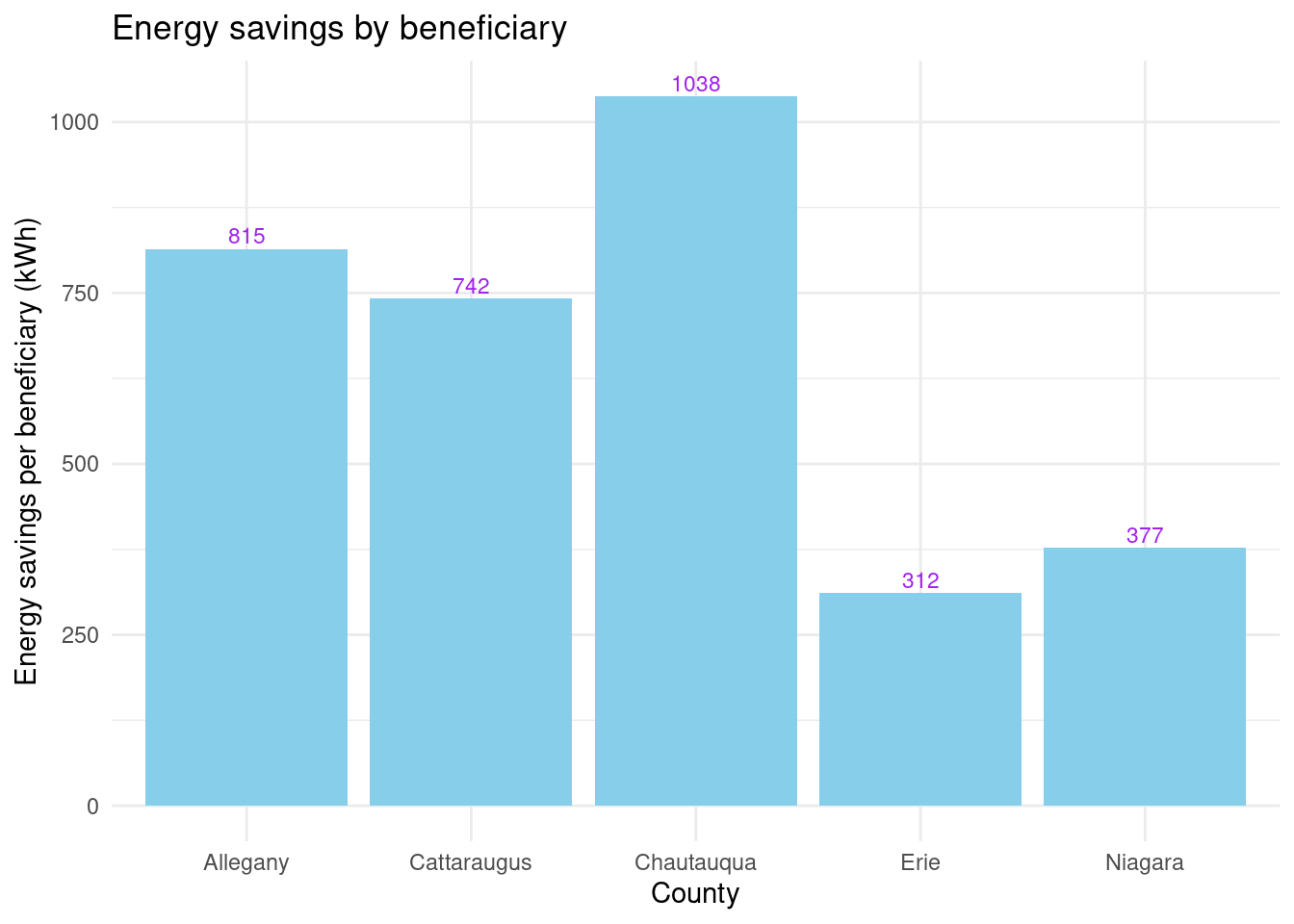
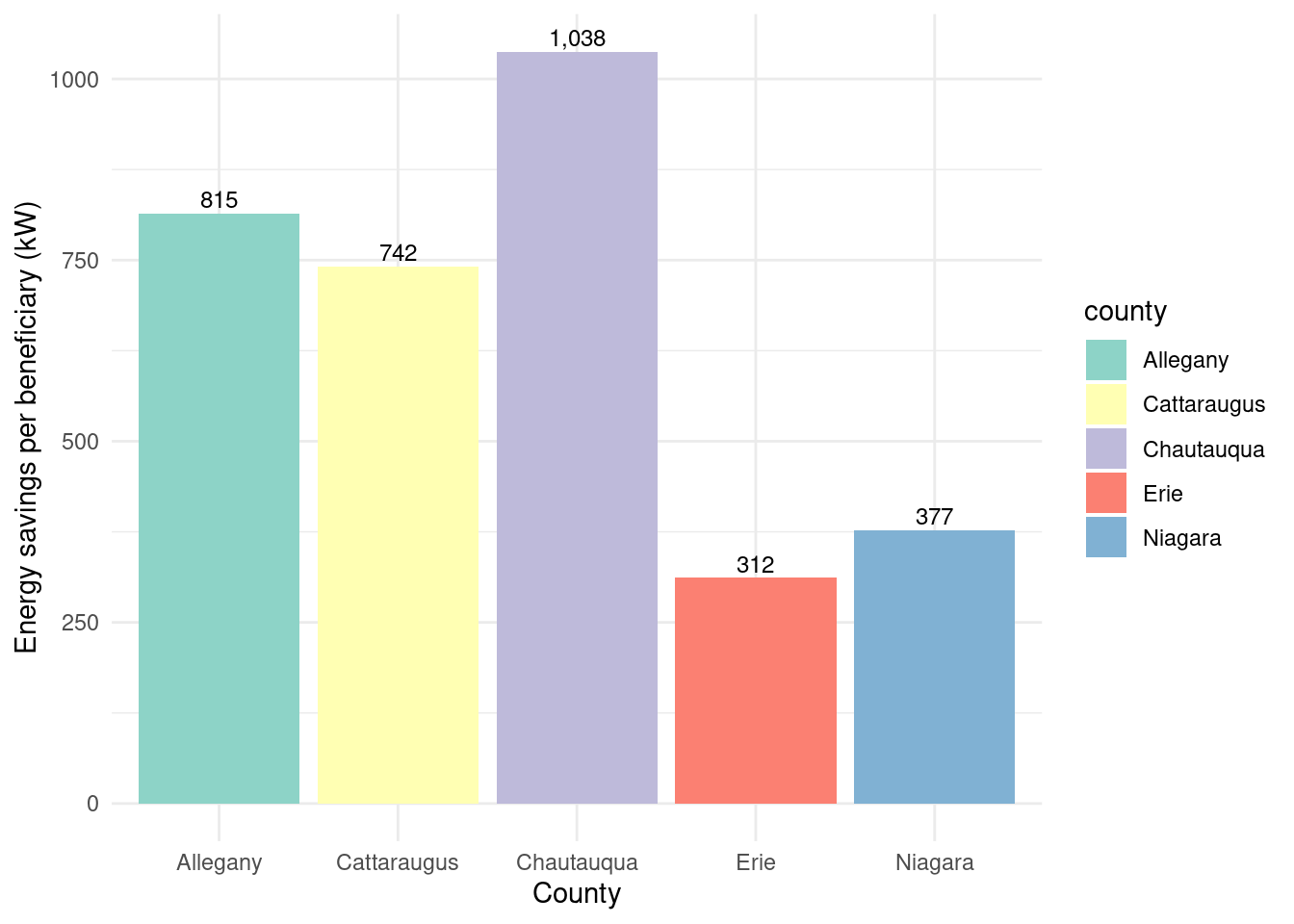
Energy savings over beneficiaries? By county: - Erie 312. - Niagara 377. - Cattaraugus 742. - Allegany 815. - Chautauqua 1038.
Graph showing energy savings by beneficiary per county:
In [31]:
county_beneficiaries_assisted_wny |>ggplot(aes(x = county, y = energysavings_by_beneficiary)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label =round(energysavings_by_beneficiary)), vjust =-0.3, color ="purple", size =3) +labs(title ="Energy savings by beneficiary", x ="County", y ="Energy savings per beneficiary (kWh)") +theme_minimal()
Erie and Niagara have the lowest energy and bill savings, but the correlation is less clear for the rural counties.
Unclear correlation by the numbers: - Cattaraugus has by far the highest bill savings by beneficiary with 822 but has considerably lower energy savings by beneficiary (742) than Chautauqua and Allegany. - Meanwhile Chautauqua and Allegany have lower bill savings/beneficiary with 519 and 469 respectivly but they have the highest energy savings by beneficiary with 1038 and 815 respectivly.
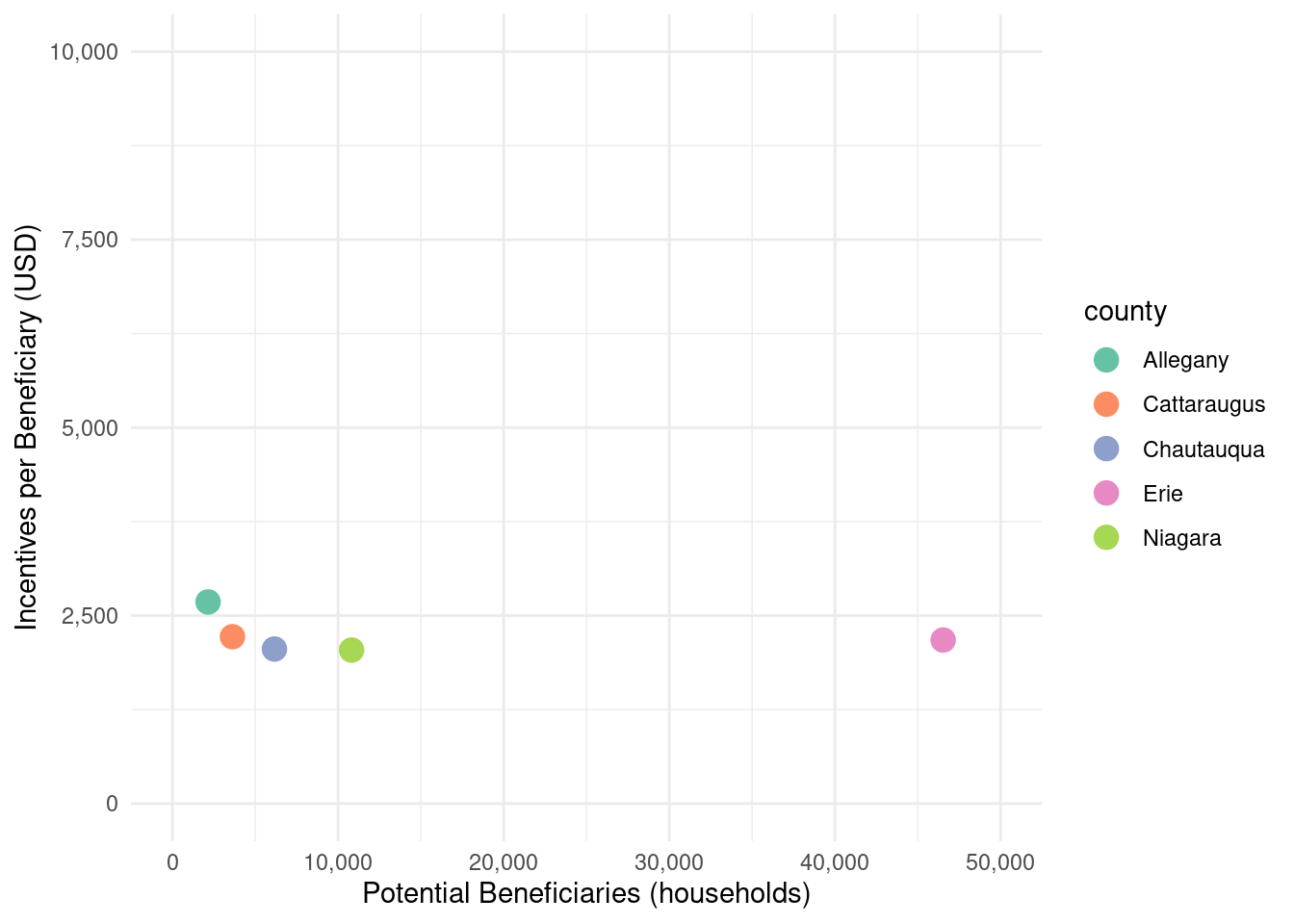
Does the average incentive amount vary depending on the size of the eligible population?
labels_for_graph <-as_labeller(c("incentives_by_beneficiary"="Incentives by Beneficiary (USD)","billsavings_by_beneficiary"="Bill Savings by Beneficiary (USD)","energysavings_by_beneficiary"="Energy Savings by Beneficiary (kWh)"))
In [35]:
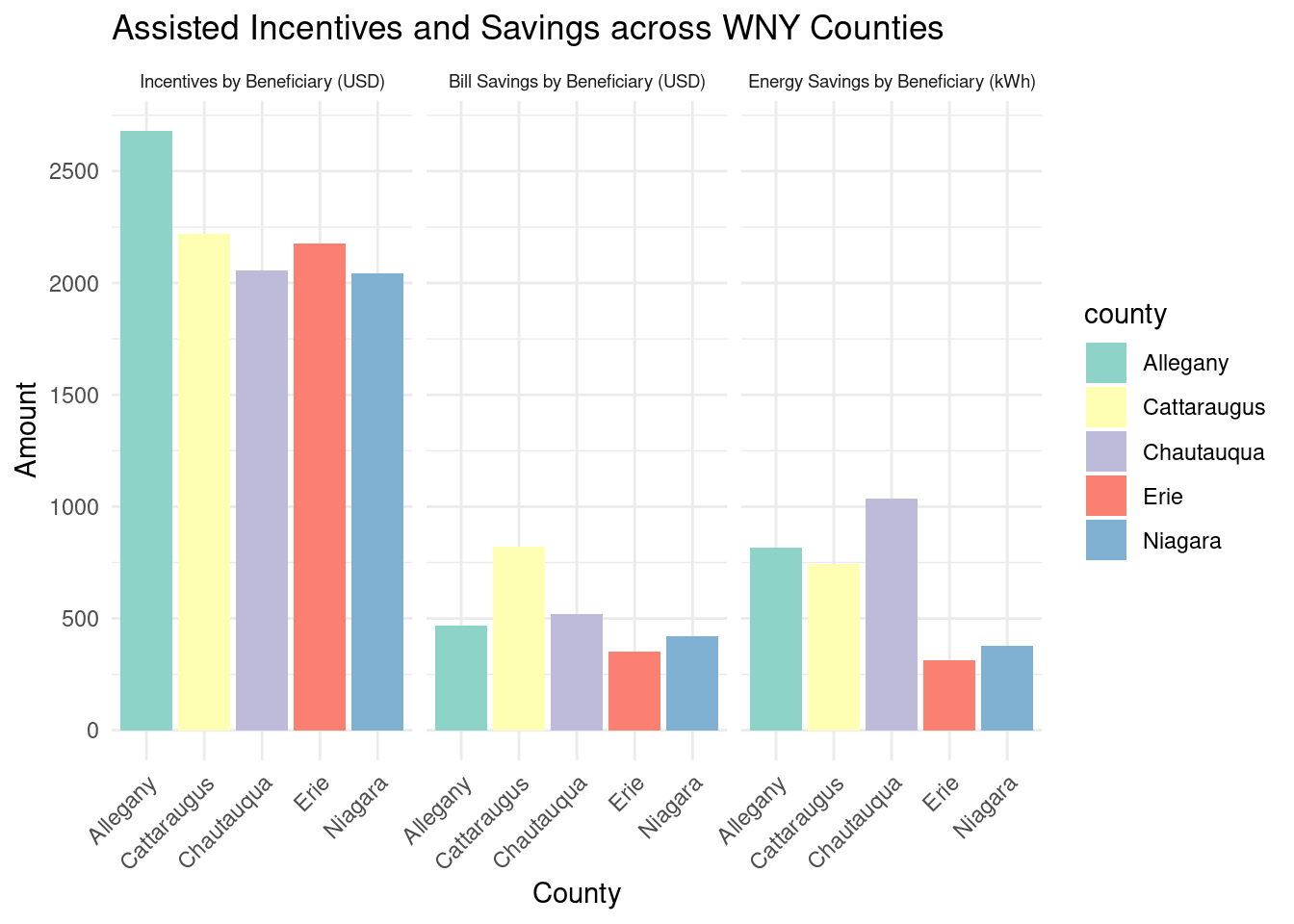
ggplot(county_beneficiaries_assisted_wny_long,aes(x = county, y = value, fill = county)) +geom_bar(stat ="identity") +facet_wrap(~category, scales ="fixed", labeller = labels_for_graph) +labs(title ="Assisted Incentives and Savings across WNY Counties",x ="County",y ="Amount") +theme_minimal() +scale_fill_brewer(palette ="Set3") +theme(axis.text.x =element_text(angle =45, hjust =1), strip.text.x =element_text(size =7)) +scale_y_continuous(breaks =seq(0, 3000, 500))
TBD
In [36]:
county_beneficiaries_assisted_wny |>ggplot(aes(x = county, y = spending_by_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Total spending per beneficiary (USD)") +geom_text(aes(label =paste0("$", scales::comma(spending_by_beneficiary, accuracy =1))),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3") +scale_y_continuous(breaks =seq(0, 10000, 1000))
Total project spending per beneficiary by county for Assisted program
In [37]:
county_beneficiaries_assisted_wny |>ggplot(aes(x = county, y = billsavings_by_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Bill savings per beneficiary (USD)") +geom_text(aes(label =paste0("$", scales::comma(billsavings_by_beneficiary, accuracy =1))),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3")
Bill savings per beneficiary by county for Assisted program
In [38]:
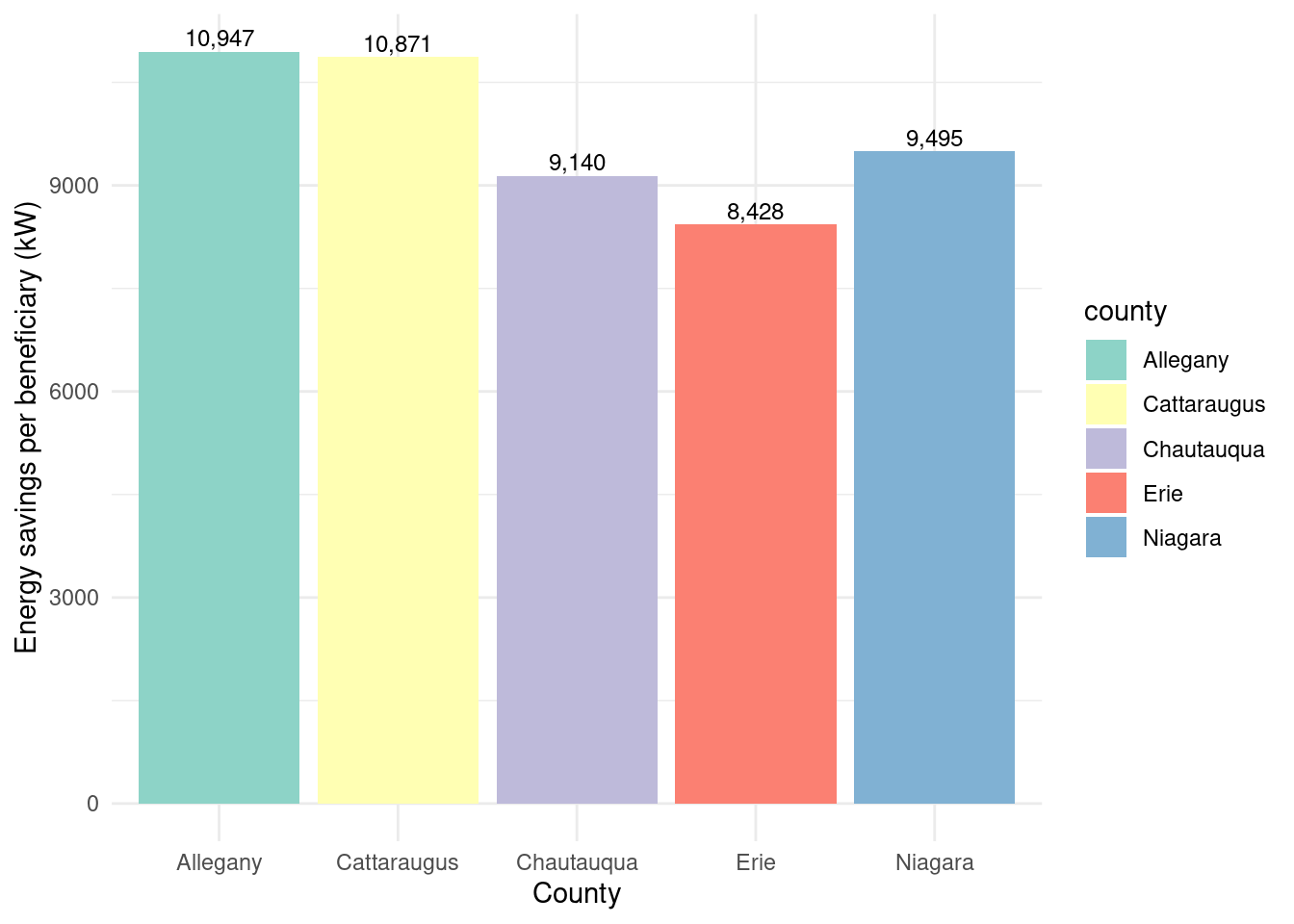
county_beneficiaries_assisted_wny |>ggplot(aes(x = county, y = energysavings_by_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Energy savings per beneficiary (kW)") +geom_text(aes(label = scales::comma(energysavings_by_beneficiary, accuracy =1)),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3")
Energy savings per beneficiary by county for Assisted program
Race
The df zcta_totalstats_assisted_wny also shows race information:
We use a left join here because we need to prioritize the zips in zip_projectstats_assisted_wny since those are the zips with projects in them. The resulting df should be 139 * 5 since there are 5 races (695 total), and it is, so we can move on.
2
The counties that are NA were removed because they did not find a match in dataset that was filtered for just midde income households.
We then get totals for the zcta_totalstats_assisted_wny and bring it down to the county level to create: county_totalstats_byrace_assisted_wny.
Assisted program incentives per household by race for WNY
Black households appear to have received the highest dollar amount of incentive per household, while Native American households received the least. Based on our analysis, this implies that more racially diverse ZCTAs received more funding.
county_totalstats_assisted_wny is also used to get a df that shows percent spending/savings
What percent of beneficiaries are white vs. black vs. native vs. other?
white 83.5%
black 10.4%
other 3.4%
asian 2.42%
native 0.301%
What percent of incentives went to white vs. black vs. native vs. other?
white 81.0
black 12.3
other 3.86
asian 2.51
native 0.318
What percent of energy savings went to white vs. black vs. native vs. other?
white 85.2
black 9.11
other 3.18
asian 2.24
native 0.304
By county, from county_pctstats_byrace_assisted_wny:
What percent of incentives went to white vs. black vs. native vs. other? - Allegany white 97.5
- Allegany black 0.101 - Allegany native 0.0802 - Allegany asian 0.283 - Allegany other 2.05
- Cattaraugus white 94.3
- Cattaraugus black 1.04
- Cattaraugus native 1.30
- Cattaraugus asian 0.792 - Cattaraugus other 2.59
- Chautauqua white 94.6
- Chautauqua black 0.695 - Chautauqua native 0.445 - Chautauqua asian 0.557 - Chautauqua other 3.72
- Erie white 77.7
- Erie black 14.7
- Erie native 0.216 - Erie asian 3.00
- Erie other 4.37
- Niagara white 92.8
- Niagara black 4.16
- Niagara native 0.732 - Niagara asian 0.692 - Niagara other 1.67
What percent of bill savings went to white vs. black vs. native vs. other?
1 Allegany white 97.6
2 Allegany black 0.112 3 Allegany native 0.0700 4 Allegany asian 0.261 5 Allegany other 1.93
6 Cattaraugus white 94.7
7 Cattaraugus black 0.632 8 Cattaraugus native 1.67
9 Cattaraugus asian 0.653 10 Cattaraugus other 2.36
11 Chautauqua white 95.0
12 Chautauqua black 0.718 13 Chautauqua native 0.339 14 Chautauqua asian 0.604 15 Chautauqua other 3.39
16 Erie white 80.3
17 Erie black 12.7
18 Erie native 0.193 19 Erie asian 2.87
20 Erie other 3.98
21 Niagara white 92.9
22 Niagara black 3.93
23 Niagara native 0.740 24 Niagara asian 0.739 25 Niagara other 1.68
What percent of energy savings went to white vs. black vs. native vs. other? 1 Allegany white 98.5
2 Allegany black -0.0236 3 Allegany native -0.0427 4 Allegany asian 0.117 5 Allegany other 1.49
6 Cattaraugus white 98.2
7 Cattaraugus black 0.155 8 Cattaraugus native -0.819 9 Cattaraugus asian 1.49
10 Cattaraugus other 0.965 11 Chautauqua white 94.8
12 Chautauqua black 0.638 13 Chautauqua native 0.339 14 Chautauqua asian 1.37
15 Chautauqua other 2.90
16 Erie white 81.1
17 Erie black 12.1
18 Erie native 0.198 19 Erie asian 2.84
20 Erie other 3.78
21 Niagara white 93.2
22 Niagara black 3.71
23 Niagara native 0.820 24 Niagara asian 0.716 25 Niagara other 1.53
In [46]:
# Incentives per HH by race by countycounty_spending_byrace_assisted_wny <- county_totalstats_byrace_assisted_wny |>rename(total_incentives = assisted_incentives_race,total_potential_beneficiaries = assisted_mihh_race, ) |>mutate(spending_per_potential_beneficiary = total_incentives / total_potential_beneficiaries, ) |>select(c(county, race, total_incentives, total_potential_beneficiaries, spending_per_potential_beneficiary))
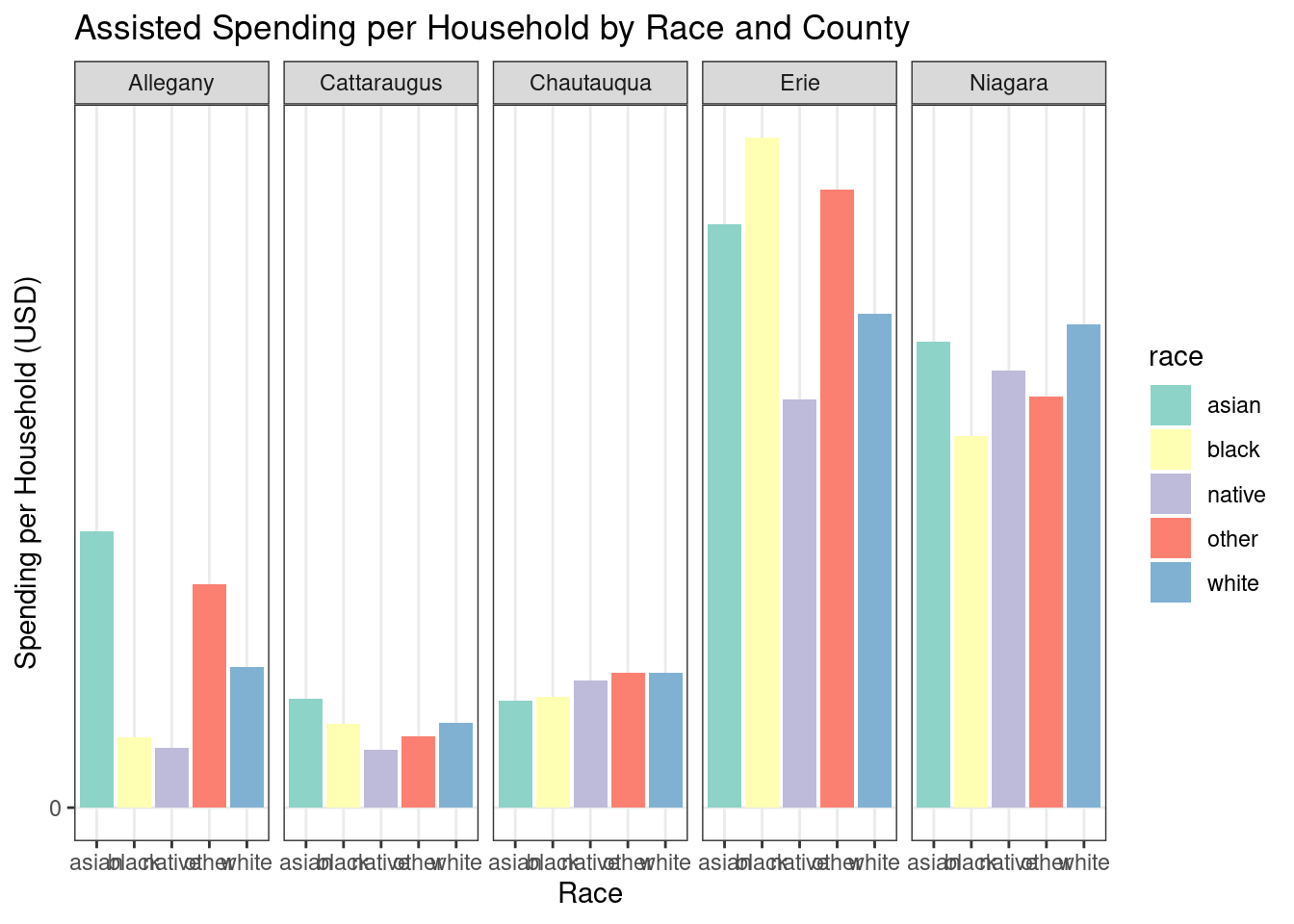
Graph showing race spending (By county)
In [47]:
county_spending_byrace_assisted_wny |>ggplot(aes(x = race, y = spending_per_potential_beneficiary, fill = race)) +geom_bar(stat ="identity") +labs(title ="Assisted Spending per Household by Race and County",x ="Race",y ="Spending per Household (USD)" ) +scale_y_continuous(labels = scales::comma, breaks =seq(0, 15000, 2500)) +theme_bw() +scale_fill_brewer(palette ="Set3") +facet_grid(~county)
In [48]:
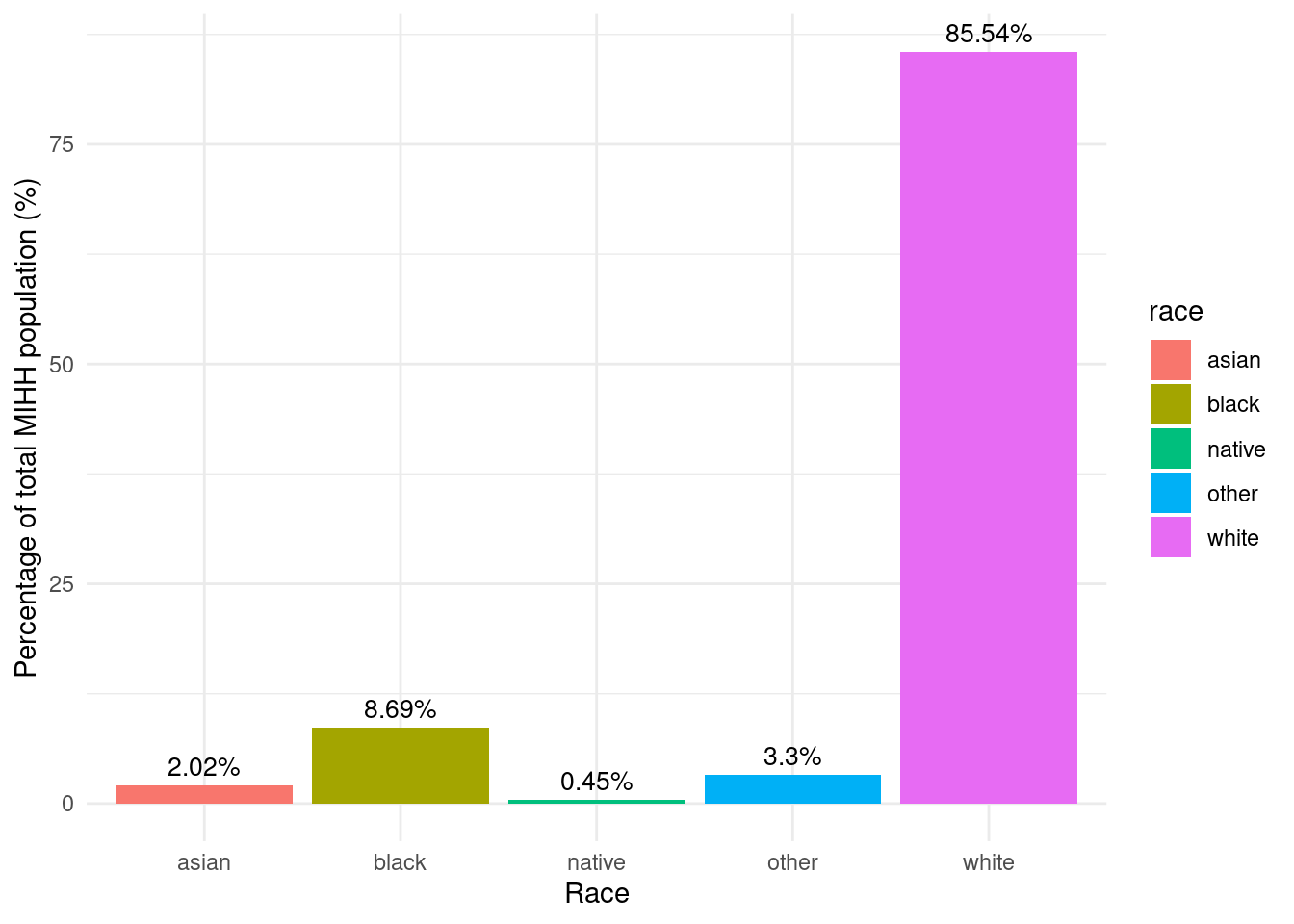
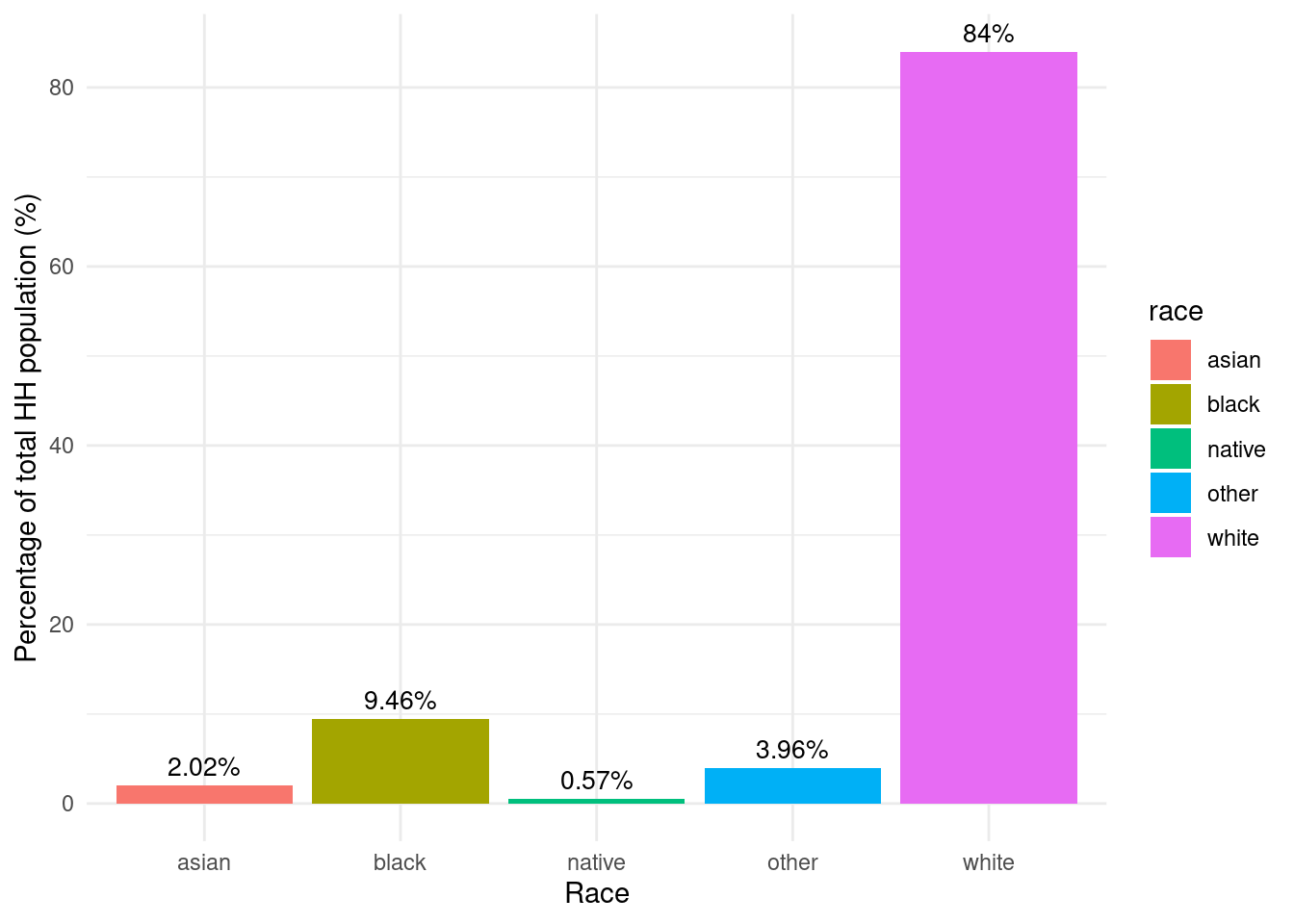
region_incentives_byrace_assisted_wny |>mutate(mihh_pct = (total_mihh /sum(total_mihh)) *100) |>mutate(mihh_pct =as.numeric(format(round(mihh_pct, 2), nsmall =2))) |>ggplot(aes(y = mihh_pct, x = race, fill = race)) +labs(y ="Percentage of total MIHH population (%)",x ="Race") +geom_bar(stat ="identity") +geom_text(aes(label =paste0(mihh_pct, "%")), vjust =-0.5, color ="black", size =3.5) +theme_minimal()
Racial makeup of middle income households in WNY
In [49]:
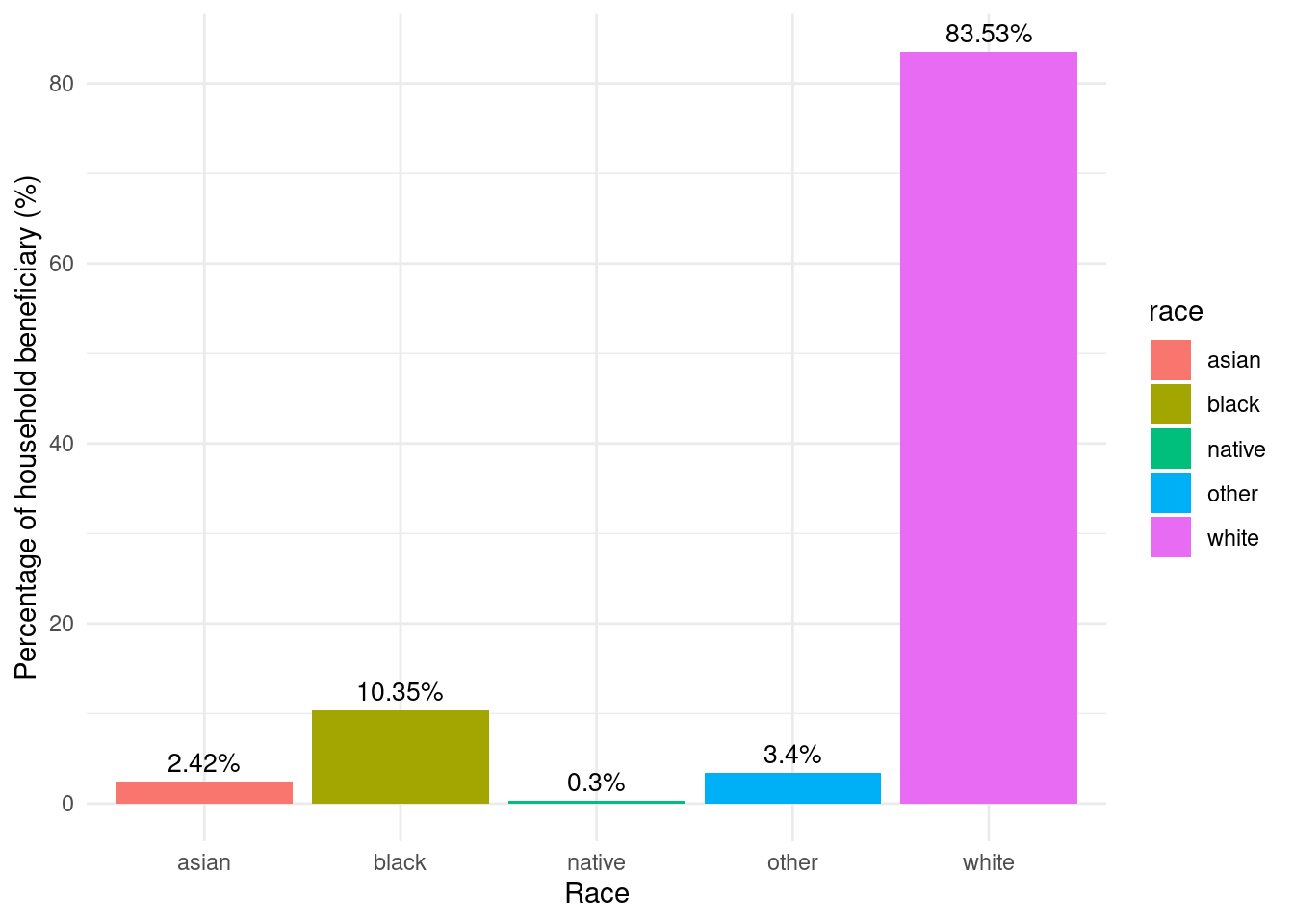
region_totalstats_byrace_assisted_wny |>mutate(beneficiary_pct = (totalprojects_total /sum(totalprojects_total)) *100) |>mutate(beneficiary_pct =as.numeric(format(round(beneficiary_pct, 2), nsmall =2))) |>ggplot(aes(y = beneficiary_pct, x = race, fill = race)) +labs(y ="Percentage of household beneficiary (%)",x ="Race") +geom_bar(stat ="identity") +geom_text(aes(label =paste0(beneficiary_pct, "%")), vjust =-0.5, color ="black", size =3.5) +theme_minimal()
Racial makeup of moderate income households in WNY
Overall numbers for Western New York, for the racial breakdown of assisted incentives per household by race, mirror the pattern of Erie County. This makes sense because Erie County is by far the largest of the five counties. Erie also has the highest Black population of any of the five counties.
One thing to note is the small size of counties other than Erie, and the low percentages of Black, Native, and Asian households.
For the index - note that limitations of this analysis include that much fewer households are surveyed for the ACS, leading to somewhat limited data on race and income by ZCTA. This means that the spending by race for each individual county is probably less accurate than the spending by race for WNY overall.
Empower
Big picture
This dataset shows the incentives, bill savings, and energy savings for all impacted lower income hh which received the Empower project for all of WNY.
One thing to note is that unlike for Assisted, we do not have numbers for private investment. This is because Empower covers the cost of these projects, so spending is interchangeable with incentives here.
Another important thing to note is while Assisted targeted mi households while Empower targets lower income households.
Scale for y is already present.
Adding another scale for y, which will replace the existing scale.
Number of completed Empower projects by year
As with Assisted, drop in the number of projects in 2020, likely due to the coronavirus pandemic. The drop here is much sharper though. Could this be bc li hh were more affected by the pandemic?
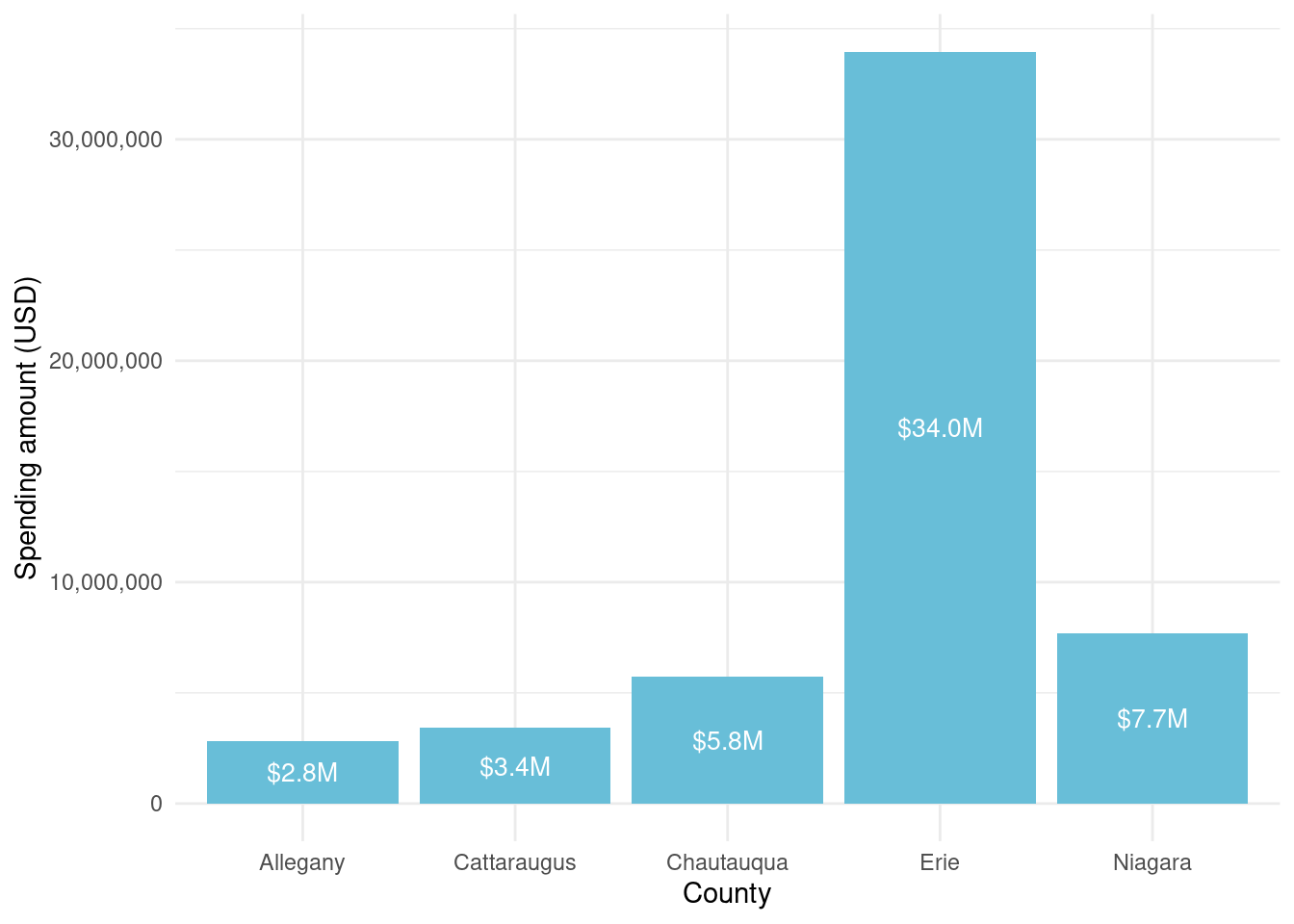
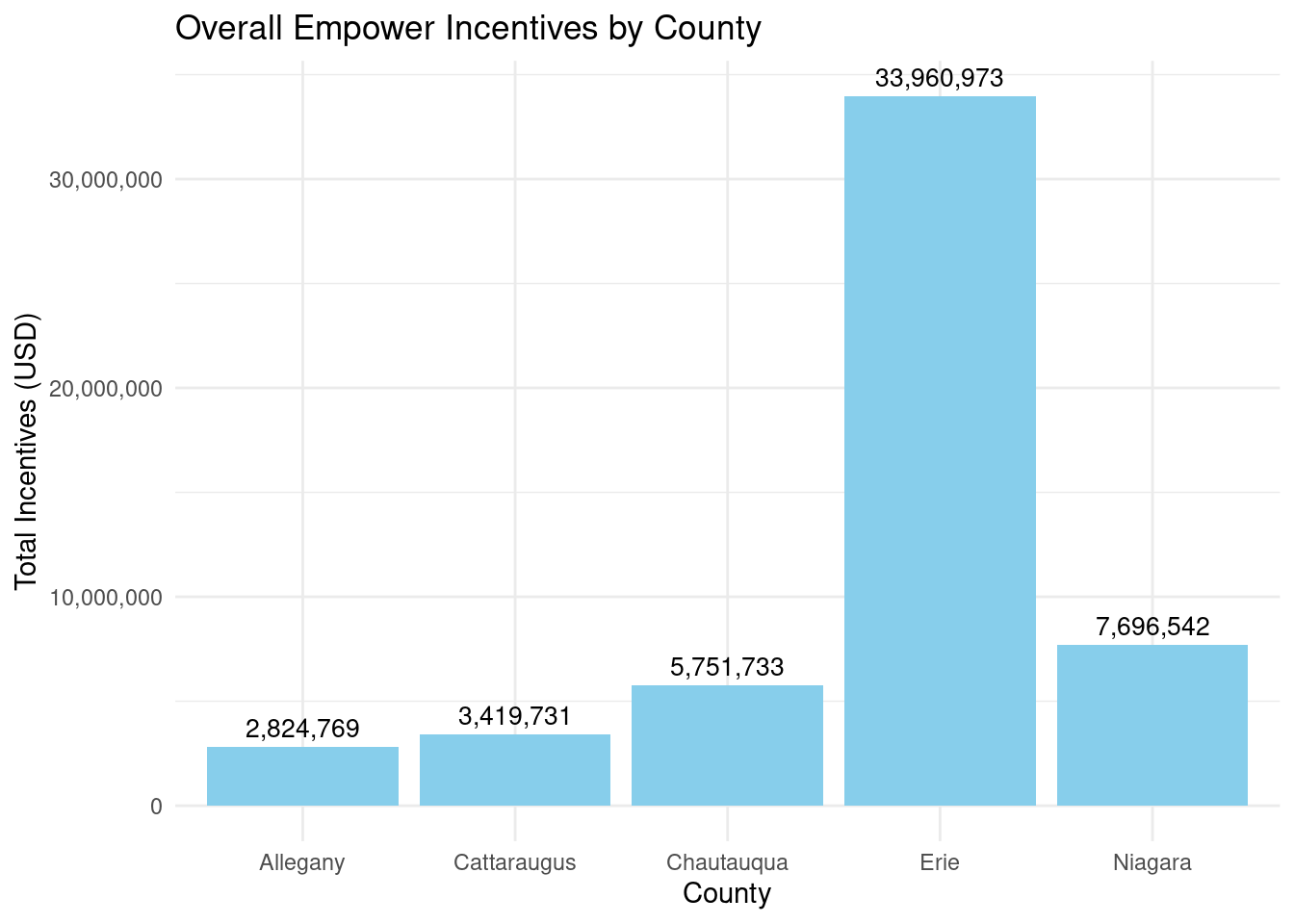
What was spent by county? - Allegany 2,824,769 - Cattaraugus 3,419,731 - Chautauqua 5,751,733 - Erie 33,960,973 - Niagara 7,696,542
As with Assisted, the majority of spending went to Erie County, which makes sense since it is the most populous.
What percent of potential beneficiaries benefitted?
In [53]:
county_lihh_wny <- zcta_hhlmi_wny |>summarise(li_households =sum(li_households, na.rm =TRUE),.by = county )
Percent of beneficiaries that benefitted by county: By county? - Allegany: 5.43% - Cattaraugus: 3.75% - Chautauqua: 3.51% - Erie: 3.43% - Niagara: 3.15%
Allegany has a somewhat higher percent of beneficiaries benefitted than other counties. This is in contrast to Assisted, which reached a 4-5x higher share of the eligible population in Erie and Niagara counties.
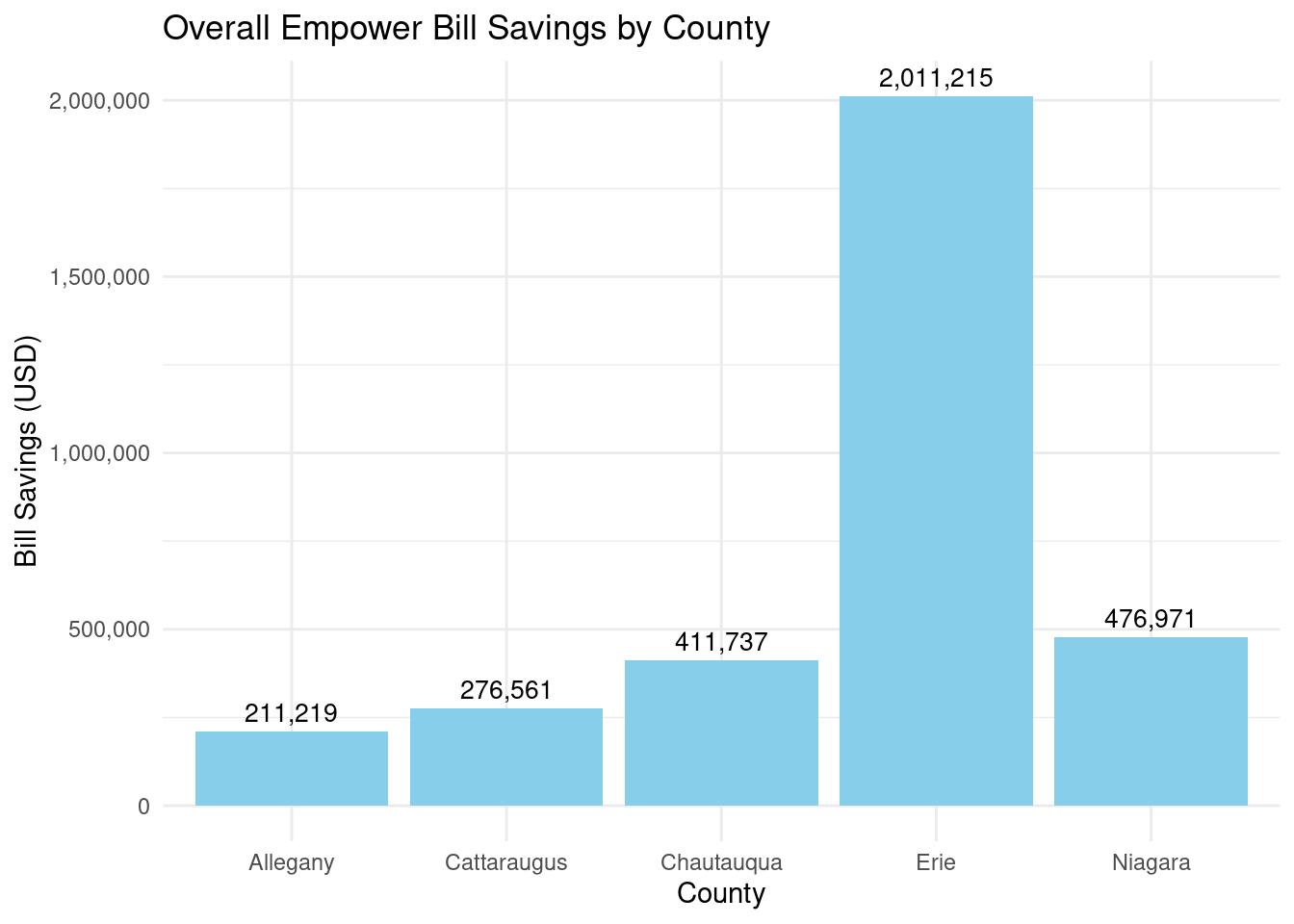
How many bill savings? Overall: $3,387,703 By county?
Allegany: 211,219
Cattaraugus: 276,561
Chautauqua: 411,737
Erie: 2,011,215
Niagara: 476,971
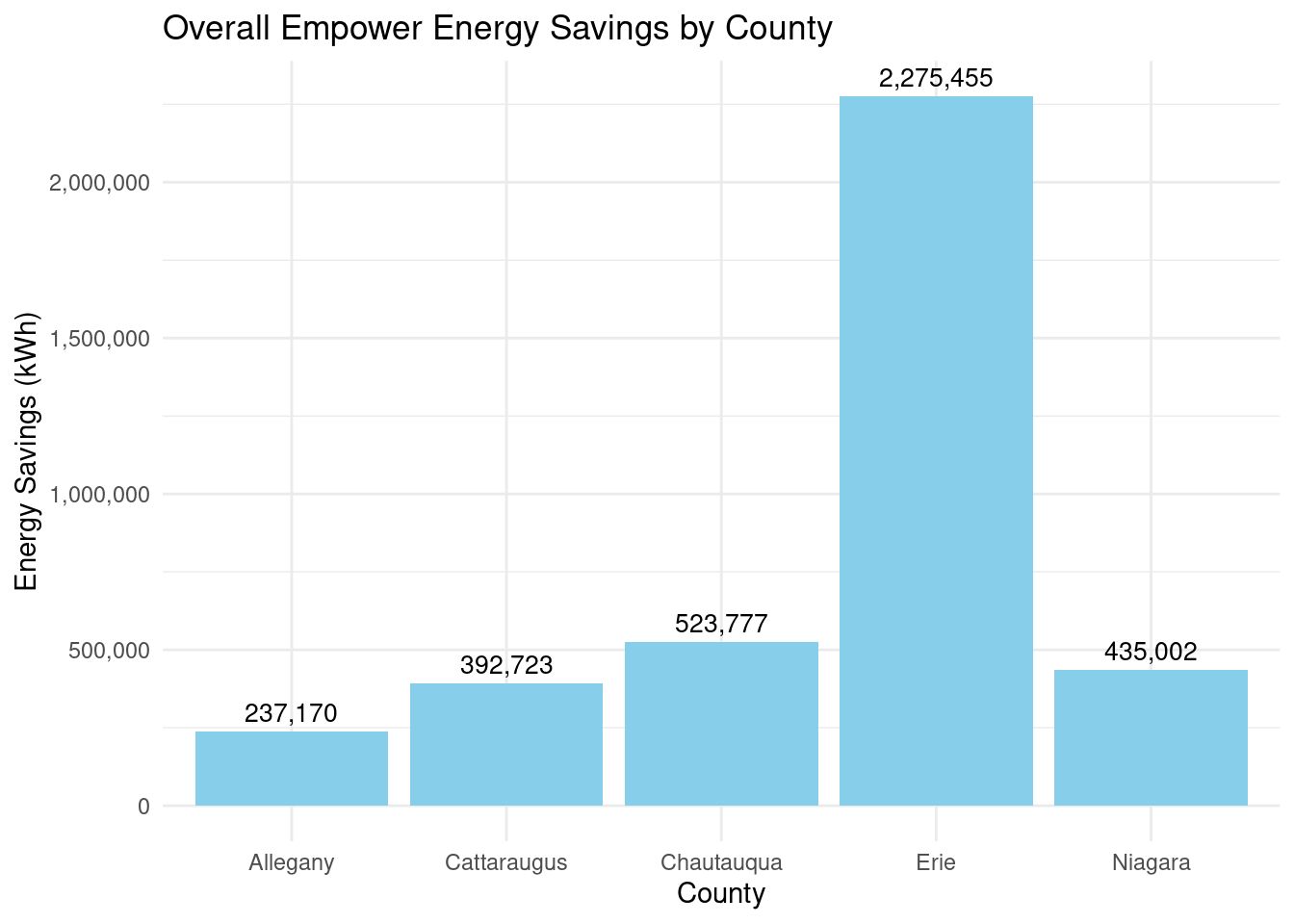
How many energy savings?
Overall: 3,864,127 kWh By county?
Allegany: 237,170
Cattaraugus: 392,723
Chautauqua: 523,777
Erie: 2,275,455
Niagara: 435,002
Graph showing overall incentives by county:
In [59]:
county_totalstats_empower_wny |>ggplot(aes(x = county, y = total_incentives)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label = scales::comma(total_incentives)), vjust =-0.5, color ="black", size =3.5) +scale_y_continuous(labels = scales::comma) +labs(title ="Overall Empower Incentives by County",x ="County",y ="Total Incentives (USD)") +theme_minimal() +theme(legend.position ="none")
Graph showing overall bill savings by county:
In [60]:
county_totalstats_empower_wny |>ggplot(aes(x = county, y = total_bill_savings)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label = scales::comma(total_bill_savings)), vjust =-0.5, color ="black", size =3.5) +scale_y_continuous(labels = scales::comma) +labs(title ="Overall Empower Bill Savings by County",x ="County",y ="Bill Savings (USD)") +theme_minimal()
Graph showing overall energy savings by county:
In [61]:
county_totalstats_empower_wny |>ggplot(aes(x = county, y = total_energy_savings)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label = scales::comma(total_energy_savings)), vjust =-0.5, color ="black", size =3.5) +scale_y_continuous(labels = scales::comma) +labs(title ="Overall Empower Energy Savings by County",x ="County",y ="Energy Savings (kWh)") +theme_minimal()
Geography
The data frame zcta_hhmi_wny_empower is created to show both hh level, income information and project level information. It is on the zcta level.
For the right join here, we know it is working because every zip in zip_projectstats_empower_wny finds a match in zcta_hhli_wny. Our final df should have 147 rows as in zip_projectstats_empower_wny, which it does so we can proceed.
The df zcta_totalstats_bybeneficiary_empower_wny is created to get total incentives numbers and bill and energy savings, as well as spending/savings by empower beneficiary.
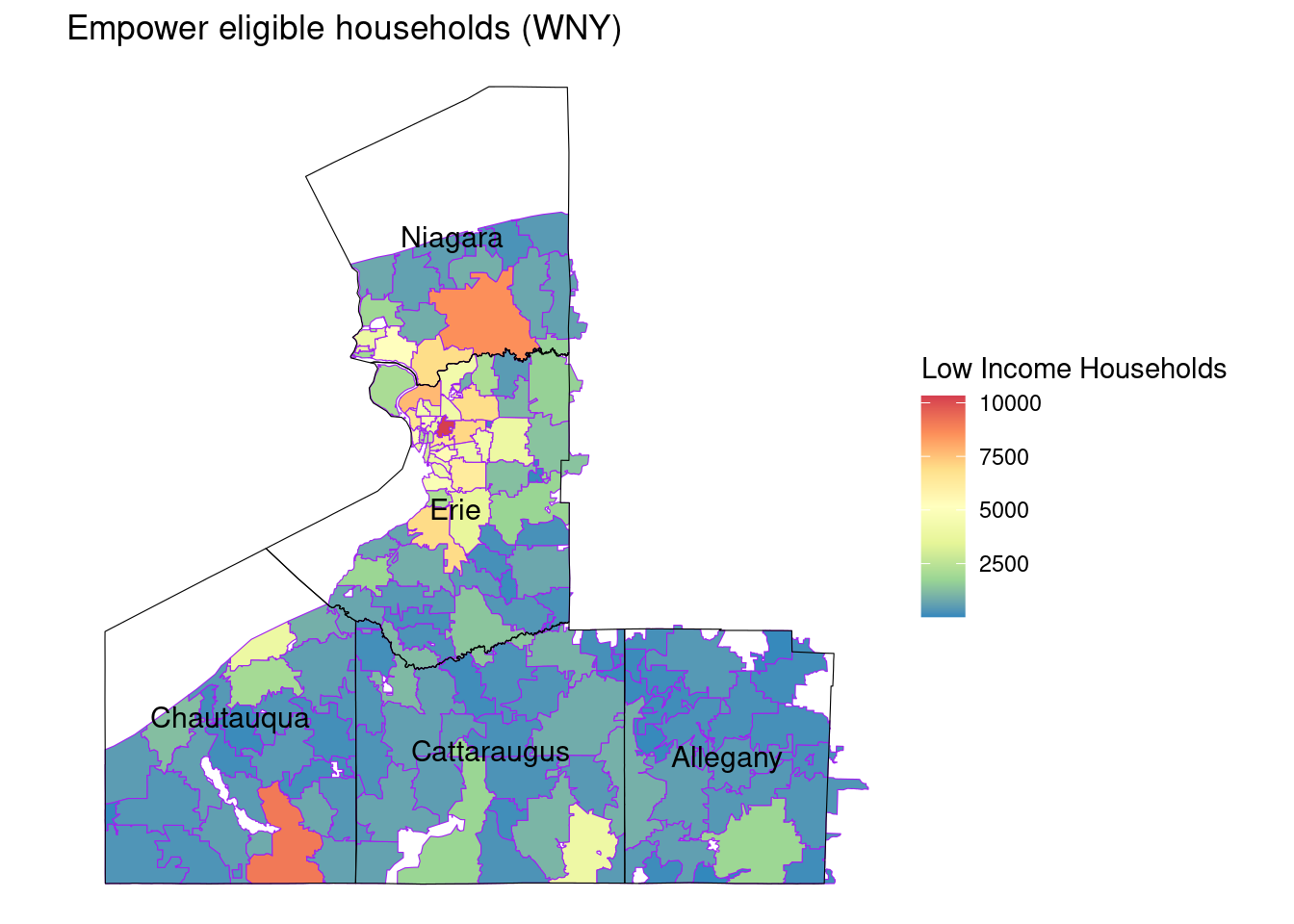
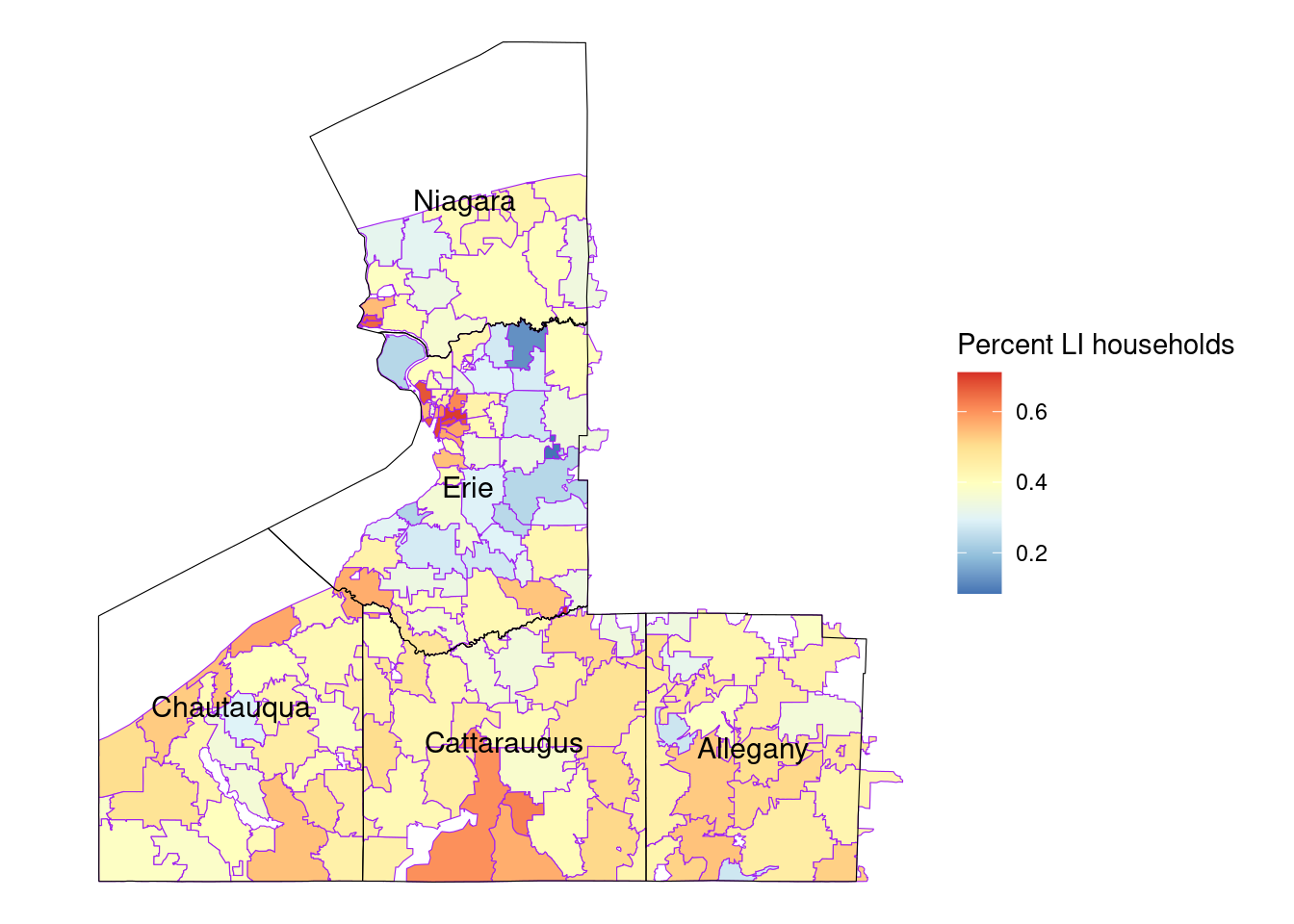
zcta_totalstats_empower_wny_sf |>ggplot() +geom_sf(aes(fill = li_households), color ="purple") +geom_sf(data = county_boundary_wny, fill =NA, color ="black", size =1) +geom_sf_text(data = county_boundary_wny, aes(label = NAME10), size =4, color ="black") +scale_fill_distiller(palette ="Spectral", name ="Low Income Households", direction =-1) +theme_void() +labs(title ="Empower eligible households (WNY)", )
Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
give correct results for longitude/latitude data
TBD
Normalized map: li hh / total hh
In [67]:
zcta_totalstats_empower_wny_sf |>ggplot() +geom_sf(aes(fill = li_households / total_households), color ="purple") +geom_sf(data = county_boundary_wny, fill =NA, color ="black", size =1) +geom_sf_text(data = county_boundary_wny, aes(label = NAME10), size =4, color ="black") +scale_fill_distiller(palette ="RdYlBu", name ="Percent LI households") +theme_void()
Warning in st_point_on_surface.sfc(sf::st_zm(x)): st_point_on_surface may not
give correct results for longitude/latitude data
Percent Empower eligible households (WNY)
Cattaraugus, Chattauqua, and Allegany counties appear to have the highest percentages of LI households. Erie appears to have the most zcta-level variation in percent LI households.
Data analysis for geography related questions at the county starts here:
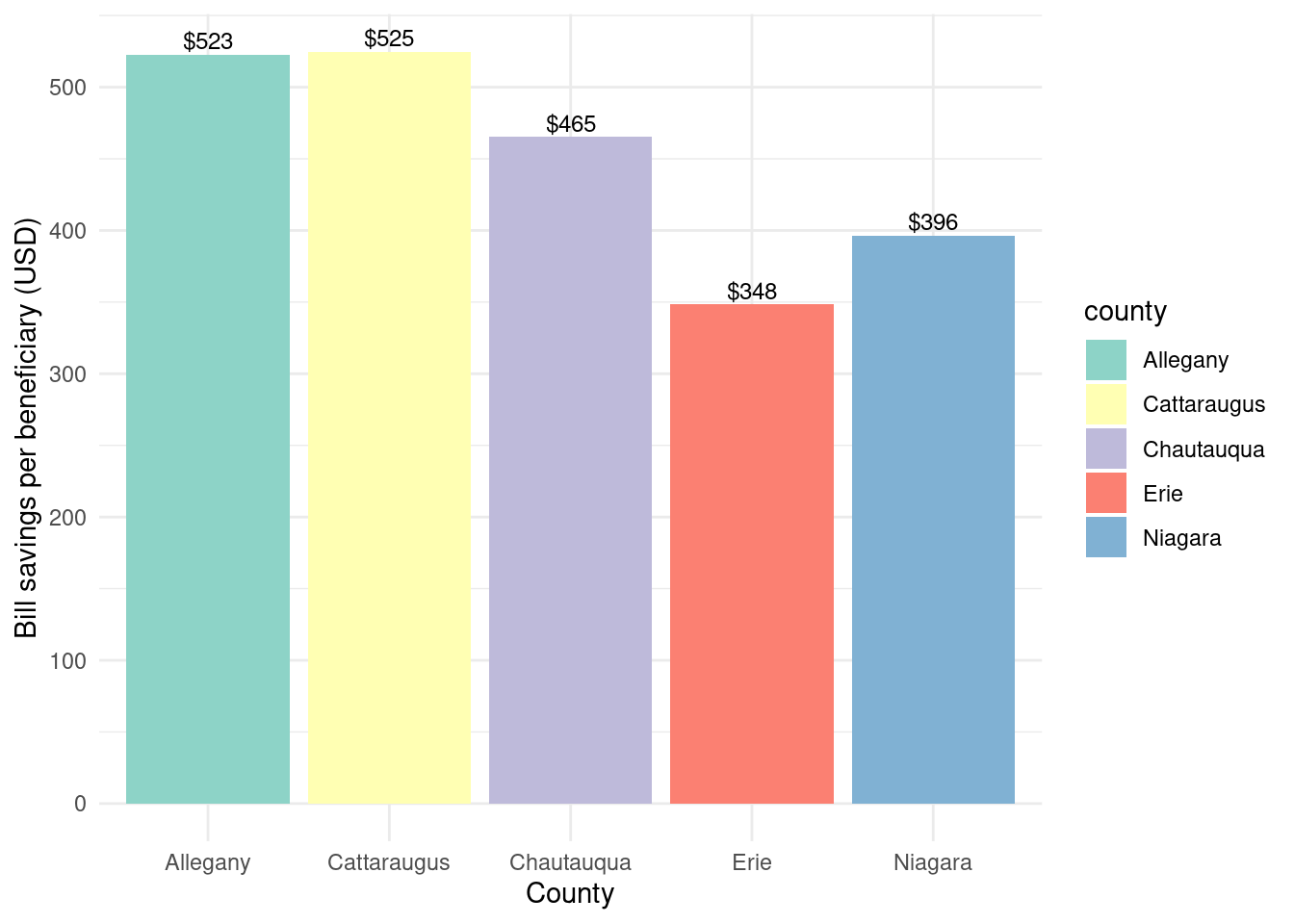
Bill savings over beneficiaries? - Allegany 523. - Cattaraugus 525. - Chautauqua 465. - Erie 348. - Niagara 396.
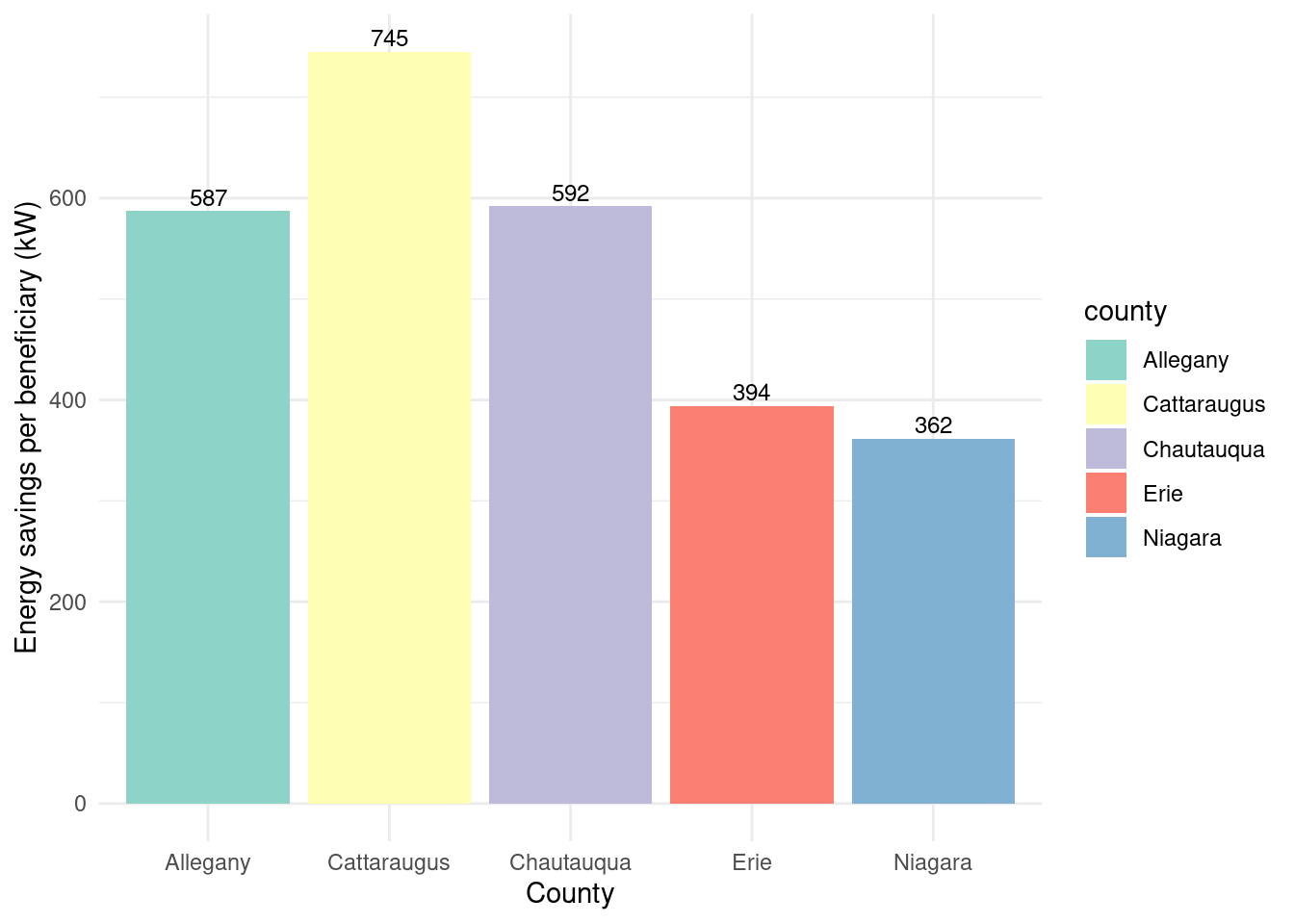
Energy savings over beneficiaries? - Allegany 587. - Cattaraugus 745. - Chautauqua 592. - Erie 394. - Niagara 362.
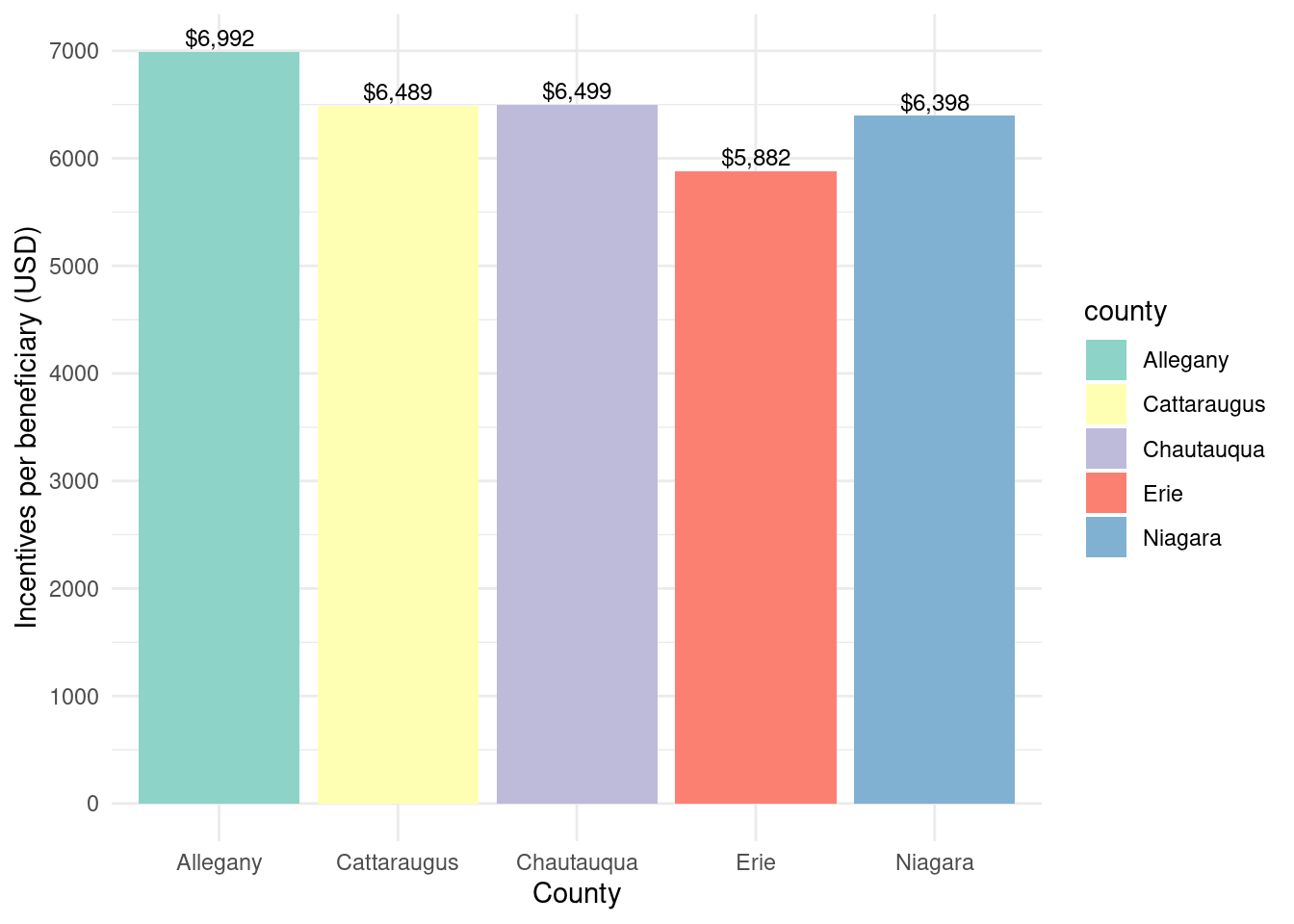
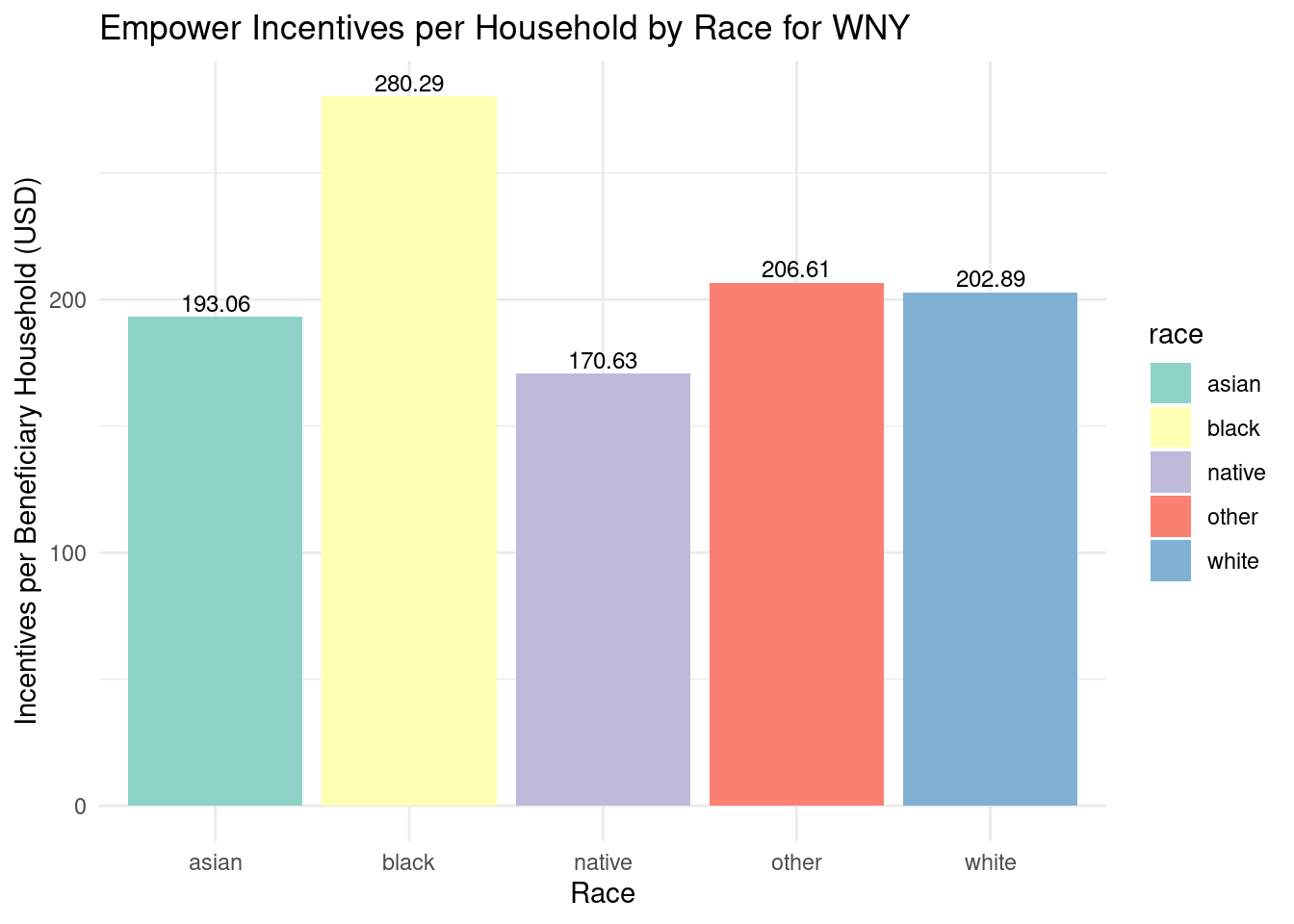
As with Assisted, for Empower Allegany had the highest incentive dollar amount per beneficiary. Cattaraugus, Chautauqua, and Niagara are fairly similar, while Erie had the lowest incentive dollar amount per benficiary. This means that Erie has the lowest incentive dollar amount per beneficiary, meaning that while the total allocation was high, it was spread across a larger number of beneficiaries. Allegany had the smallest percentage of money but had the highest incentive dollar amount per beneficiary. This suggests that fewer individuals received assistance, but the assistance per person was larger. Overall, a range of about 1k comparing the highest (Allegany) to the lowest (Erie).
Allegany and Chautauqua had somewhat higher bill savings over beneficiaries than other counties. Cattauraugus had the highest energy savings per beneficiary, followed by Chautauqua and Allegany.
The variation in energy savings per beneficiary could be explained by rural counties having higher energy bills (as with assisted).
empower_graph_label <-as_labeller(c("incentives_per_beneficiary"="Incentives per Beneficiary (USD)","billsavings_per_beneficiary"="Bill Savings per Beneficiary (USD)","energysavings_per_beneficiary"="Energy Savings per Beneficiary (kWh)"))
In [77]:
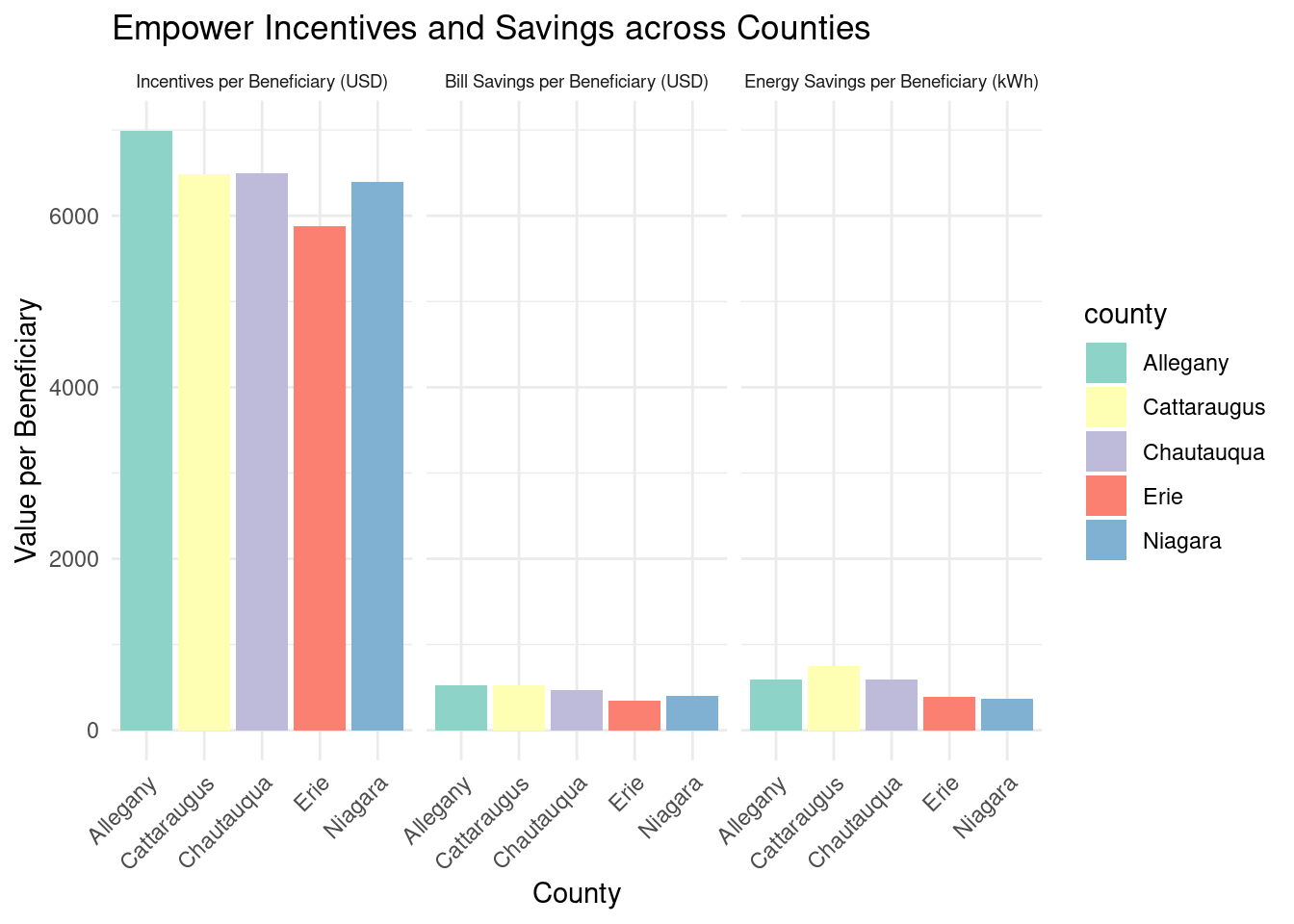
county_beneficiaries_empower_wny_long |>ggplot(aes(x = county, y = value, fill = county)) +geom_bar(stat ="identity") +facet_wrap(~category, scales ="fixed", labeller = empower_graph_label) +labs(title ="Empower Incentives and Savings across Counties",x ="County",y ="Value per Beneficiary") +theme_minimal() +scale_fill_brewer(palette ="Set3") +theme(axis.text.x =element_text(angle =45, hjust =1), strip.text.x =element_text(size =7))
TBD
In [78]:
county_beneficiaries_empower_wny |>ggplot(aes(x = county, y = incentives_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Incentives per beneficiary (USD)") +geom_text(aes(label =paste0("$", scales::comma(incentives_per_beneficiary, accuracy =1))),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3") +scale_y_continuous(breaks =seq(0, 10000, 1000))
Total incentives per beneficiary by county for Empower program
In [79]:
county_beneficiaries_empower_wny |>ggplot(aes(x = county, y = billsavings_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Bill savings per beneficiary (USD)") +geom_text(aes(label =paste0("$", scales::comma(billsavings_per_beneficiary, accuracy =1))),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3")
Bill savings per beneficiary by county for Empower program
In [80]:
county_beneficiaries_empower_wny |>ggplot(aes(x = county, y = energysavings_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Energy savings per beneficiary (kW)") +geom_text(aes(label = scales::comma(energysavings_per_beneficiary, accuracy =1)),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3")
Energy savings per beneficiary by county for Empower program
What percent of beneficiaries are white vs. black vs. native vs. other? 1 Allegany white 98.2
2 Allegany black 0.237 3 Allegany native 0.486 4 Allegany asian 0.0603 5 Allegany other 1.05
6 Cattaraugus white 93.2
7 Cattaraugus black 1.37
8 Cattaraugus native 2.06
9 Cattaraugus asian 0.511 10 Cattaraugus other 2.87
11 Chautauqua white 91.8
12 Chautauqua black 2.41
13 Chautauqua native 0.361 14 Chautauqua asian 0.580 15 Chautauqua other 4.86
16 Erie white 64.1
17 Erie black 25.8
18 Erie native 0.555 19 Erie asian 3.05
20 Erie other 6.53
21 Niagara white 83.2
22 Niagara black 10.6
23 Niagara native 1.01
24 Niagara asian 0.804 25 Niagara other 4.47
What percent of spending went to white vs. black vs. native vs. other? 1 Allegany white 98.2
2 Allegany black 0.236 3 Allegany native 0.504 4 Allegany asian 0.0590 5 Allegany other 1.04
6 Cattaraugus white 93.3
7 Cattaraugus black 1.32
8 Cattaraugus native 2.02
9 Cattaraugus asian 0.491 10 Cattaraugus other 2.84
11 Chautauqua white 92.1
12 Chautauqua black 2.30
13 Chautauqua native 0.324 14 Chautauqua asian 0.507 15 Chautauqua other 4.75
16 Erie white 64.1
17 Erie black 25.8
18 Erie native 0.553 19 Erie asian 3.09
20 Erie other 6.46
21 Niagara white 83.1
22 Niagara black 10.6
23 Niagara native 0.992 24 Niagara asian 0.772 25 Niagara other 4.49
What percent of bill savings went to white vs. black vs. native vs. other? 1 Allegany white 98.2
2 Allegany black 0.218 3 Allegany native 0.476 4 Allegany asian 0.0661 5 Allegany other 1.03
6 Cattaraugus white 93.7
7 Cattaraugus black 1.31
8 Cattaraugus native 1.68
9 Cattaraugus asian 0.465 10 Cattaraugus other 2.88
11 Chautauqua white 92.8
12 Chautauqua black 2.08
13 Chautauqua native 0.328 14 Chautauqua asian 0.529 15 Chautauqua other 4.32
16 Erie white 62.1
17 Erie black 27.5
18 Erie native 0.567 19 Erie asian 3.19
20 Erie other 6.61
21 Niagara white 83.9
22 Niagara black 10.0
23 Niagara native 1.04
24 Niagara asian 0.789 25 Niagara other 4.20
What percent of energy savings went to white vs. black vs. native vs. other? 1 Allegany white 98.2
2 Allegany black 0.312 3 Allegany native 0.550 4 Allegany asian 0.0591 5 Allegany other 0.920 6 Cattaraugus white 93.7
7 Cattaraugus black 1.01
8 Cattaraugus native 1.95
9 Cattaraugus asian 0.363 10 Cattaraugus other 3.01
11 Chautauqua white 93.1
12 Chautauqua black 1.89
13 Chautauqua native 0.342 14 Chautauqua asian 0.556 15 Chautauqua other 4.07
16 Erie white 63.0
17 Erie black 26.9
18 Erie native 0.541 19 Erie asian 3.13
20 Erie other 6.41
21 Niagara white 82.2
22 Niagara black 11.4
23 Niagara native 1.03
24 Niagara asian 0.762 25 Niagara other 4.67
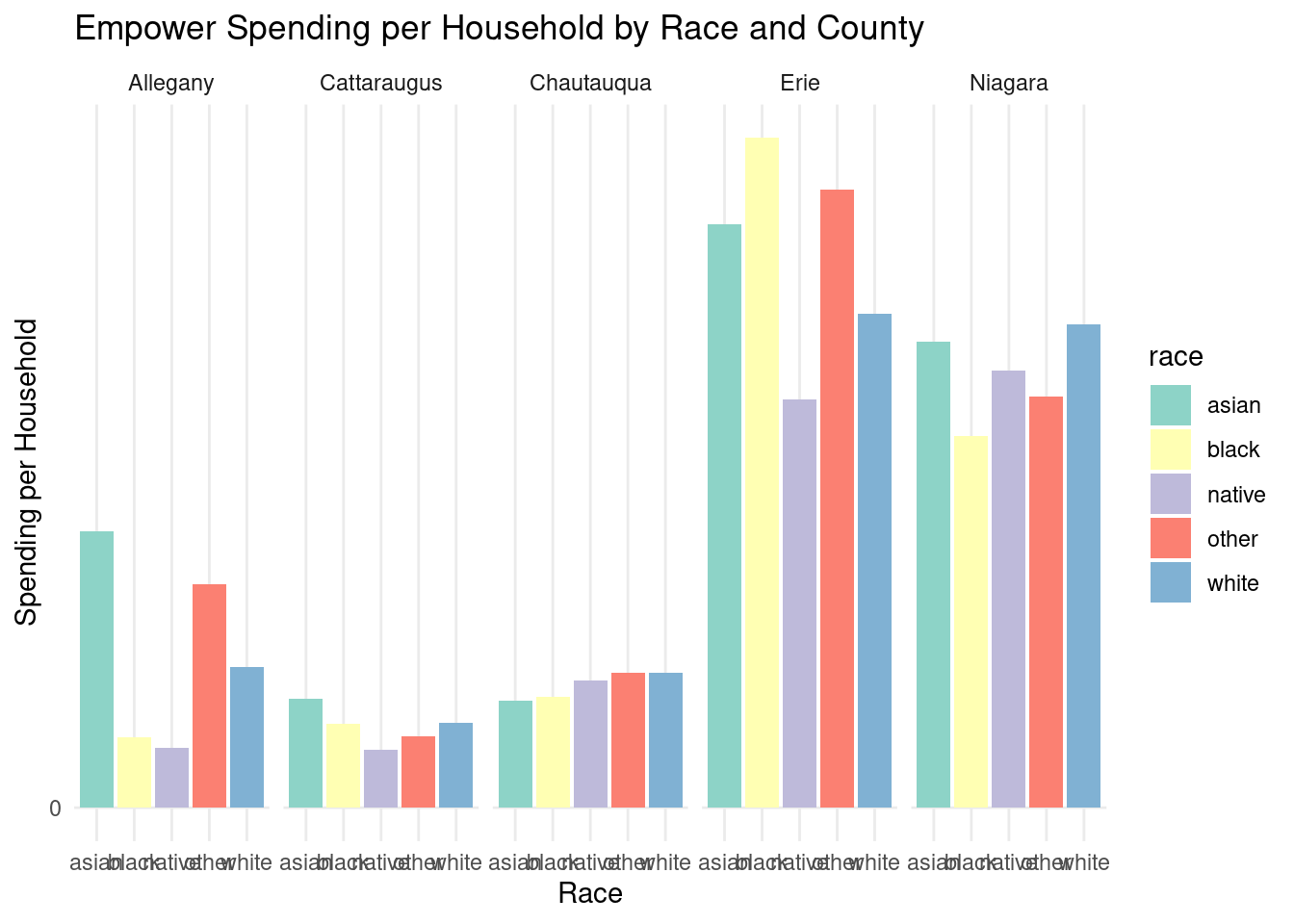
county_spending_byrace_assisted_wny |>ggplot(aes(x = race, y = spending_per_potential_beneficiary, fill = race)) +geom_bar(stat ="identity") +labs(title ="Empower Spending per Household by Race and County",x ="Race",y ="Spending per Household" ) +scale_y_continuous(labels = scales::comma, breaks =seq(0, 15000, 2500)) +theme_minimal() +scale_fill_brewer(palette ="Set3") +facet_grid(~county)
In [90]:
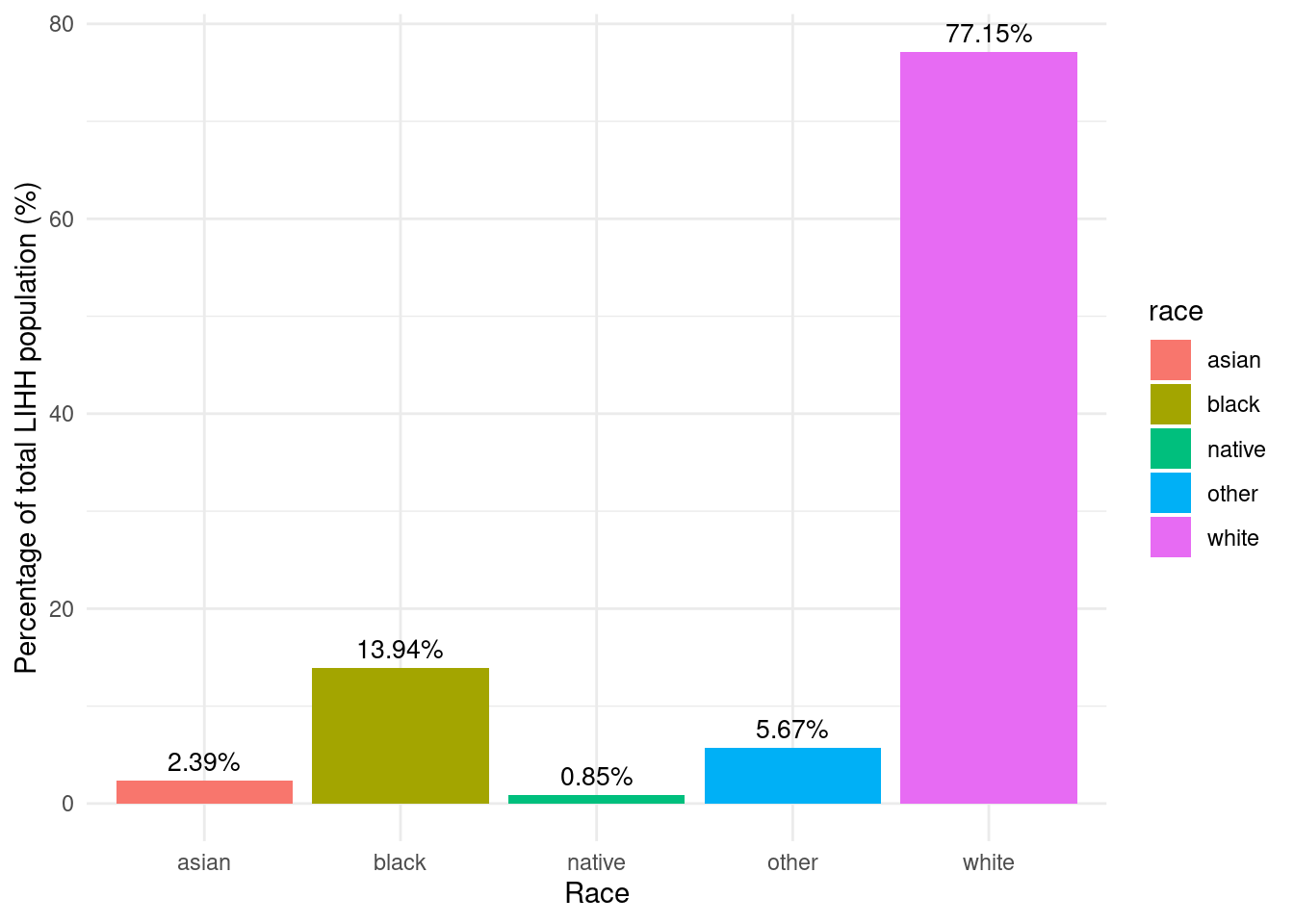
region_incentives_byrace_empower_wny |>mutate(lihh_pct = (total_potential_beneficiaries /sum(total_potential_beneficiaries)) *100) |>mutate(lihh_pct =as.numeric(format(round(lihh_pct, 2), nsmall =2))) |>ggplot(aes(y = lihh_pct, x = race, fill = race)) +labs(y ="Percentage of total LIHH population (%)",x ="Race") +geom_bar(stat ="identity") +geom_text(aes(label =paste0(lihh_pct, "%")), vjust =-0.5, color ="black", size =3.5) +theme_minimal()
Racial makeup of low income households in WNY
In [91]:
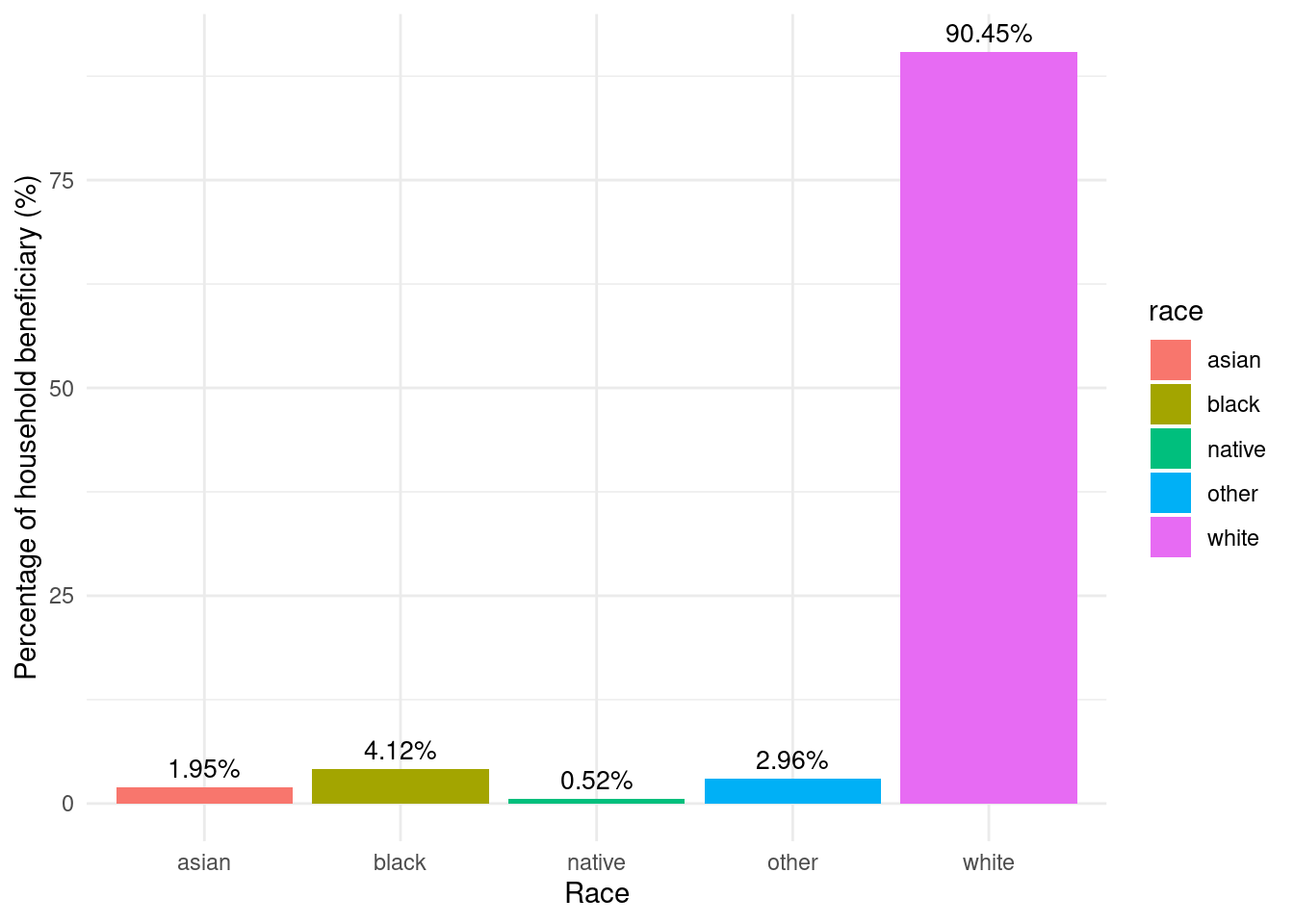
region_totalstats_byrace_empower_wny |>mutate(beneficiary_pct = (empower_totalprojects_race /sum(empower_totalprojects_race)) *100) |>mutate(beneficiary_pct =as.numeric(format(round(beneficiary_pct, 2), nsmall =2))) |>ggplot(aes(y = beneficiary_pct, x = race, fill = race)) +labs(y ="Percentage of household beneficiary (%)",x ="Race") +geom_bar(stat ="identity") +geom_text(aes(label =paste0(beneficiary_pct, "%")), vjust =-0.5, color ="black", size =3.5) +theme_minimal()
Racial makeup of Empower program’s beneficiary households in WNY
Counties vary in terms of the racial demographics of Empower spending by household. Some of this analysis may be complicated by the small amount of data available for some smaller counties. Estimates for Empower spending by race are probably less accurate by county than for Western NY overall.
Black households receive the highest levels of spending per household for both Allegany and Erie counties, as well as in Niagara (though this is a very slight difference).
NY Sun Residential
The df region_projectstats_nysun_res_wny was created to show the overall number of projects, incentives, energy capacity, and energy generation in all of WNY.
One important thing to note for NYSun is that there are no income requirements. It can be applied to all households even if they are not lmi.
The df wny_countystats_nysunresi was created to show the overall number of projects, incentives, energy capacity, and energy generation by county in WNY.
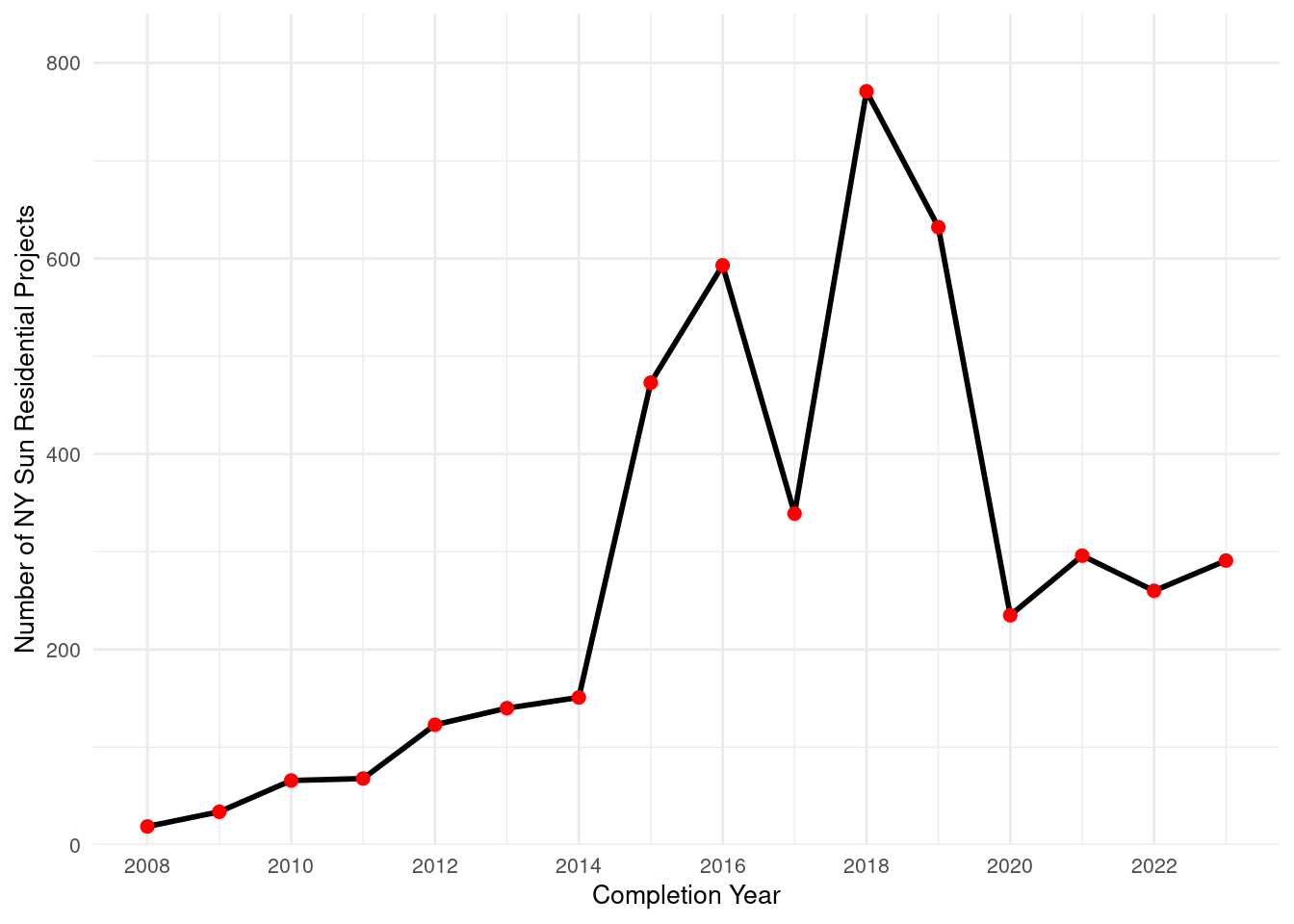
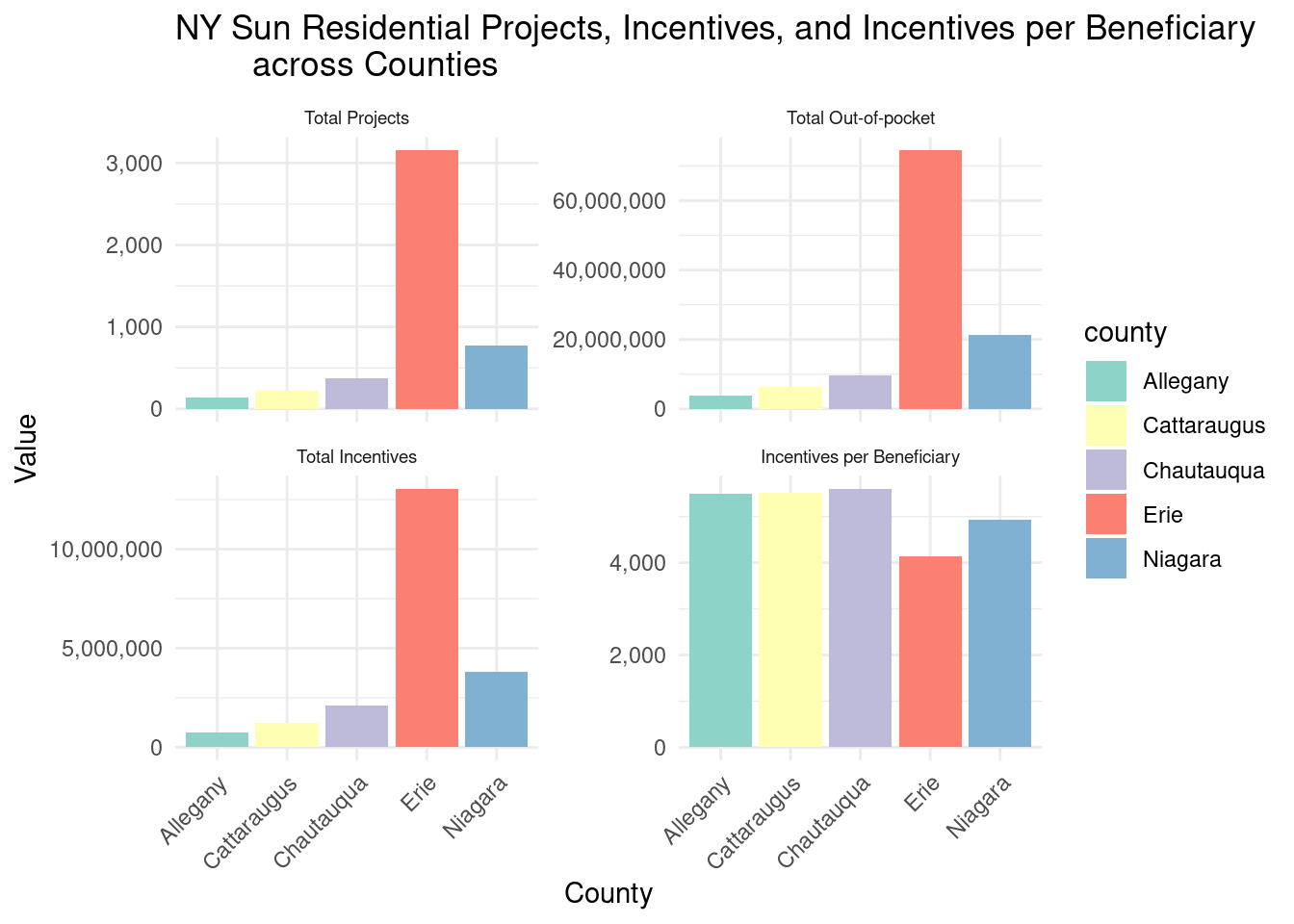
Overall, there were 4,662 projects for Western NY during this time period.
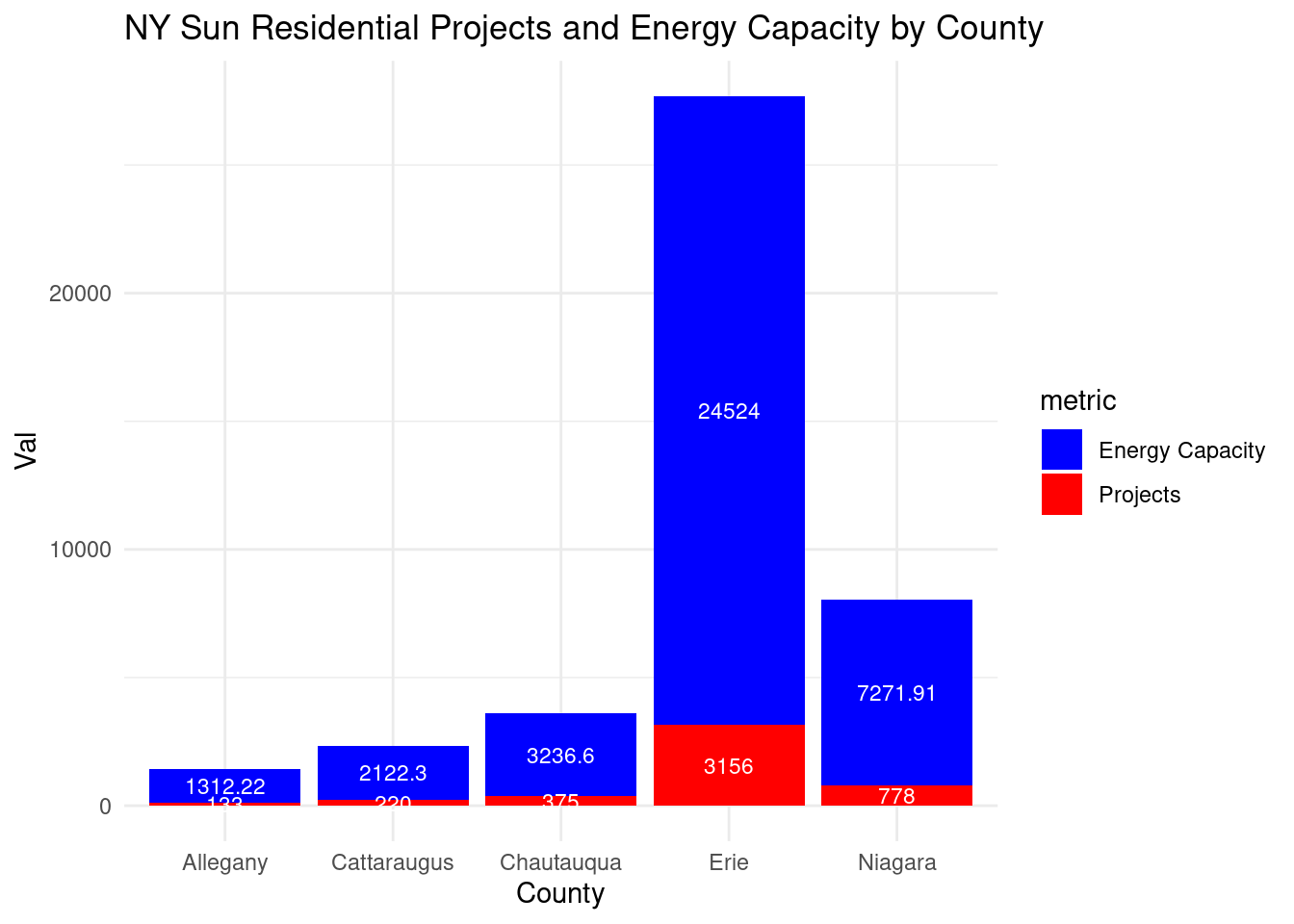
It seems like the incentives might be influencing the energy capacity generated by county. This could be because greater incentives = greater amt of projects.
Checking: Yes, if we look at amt of projects in desc order, it stays the same: 1 Erie 3156 2 Niagara 778 3 Chautauqua 375 4 Cattaraugus 220 5 Allegany 133
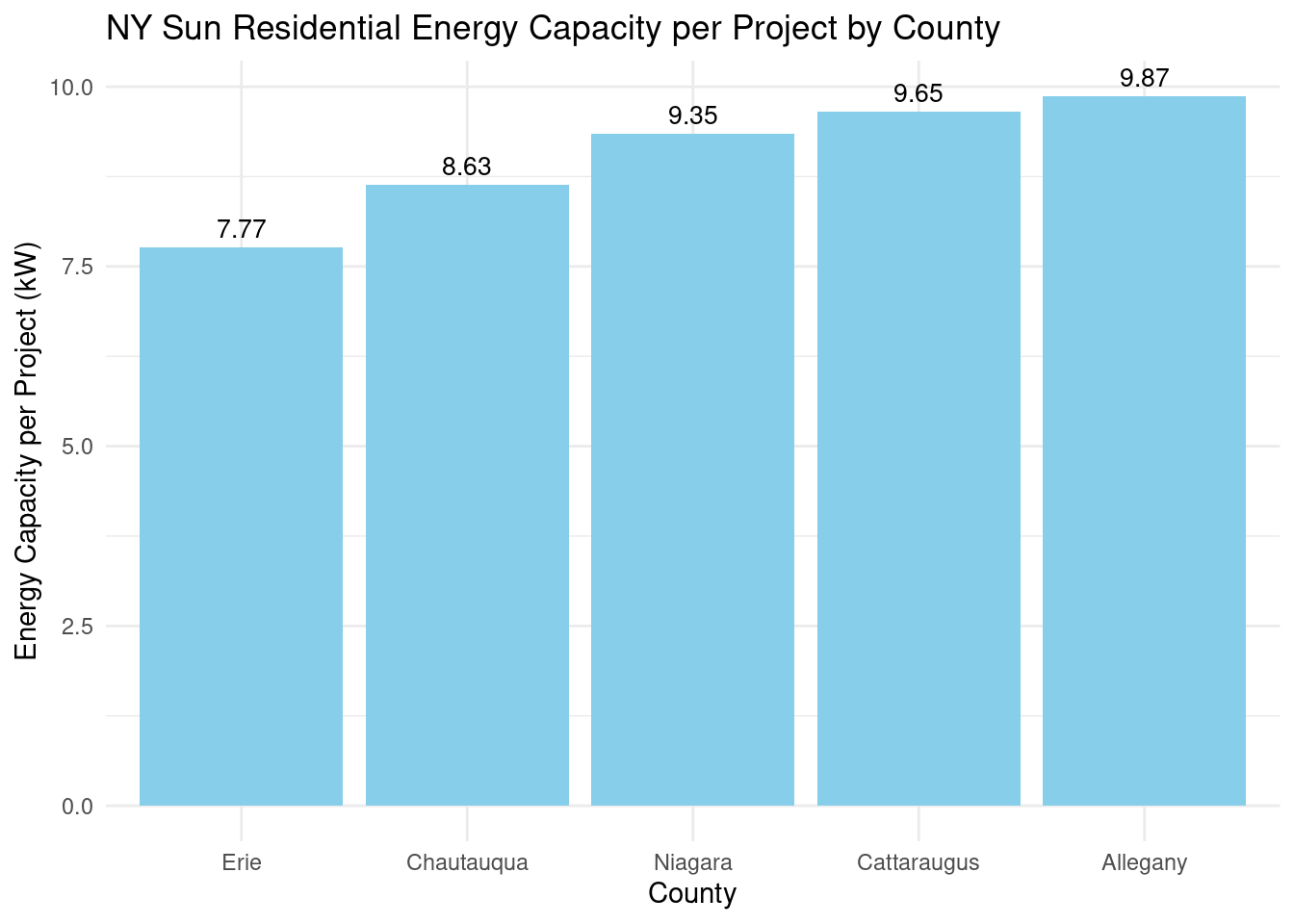
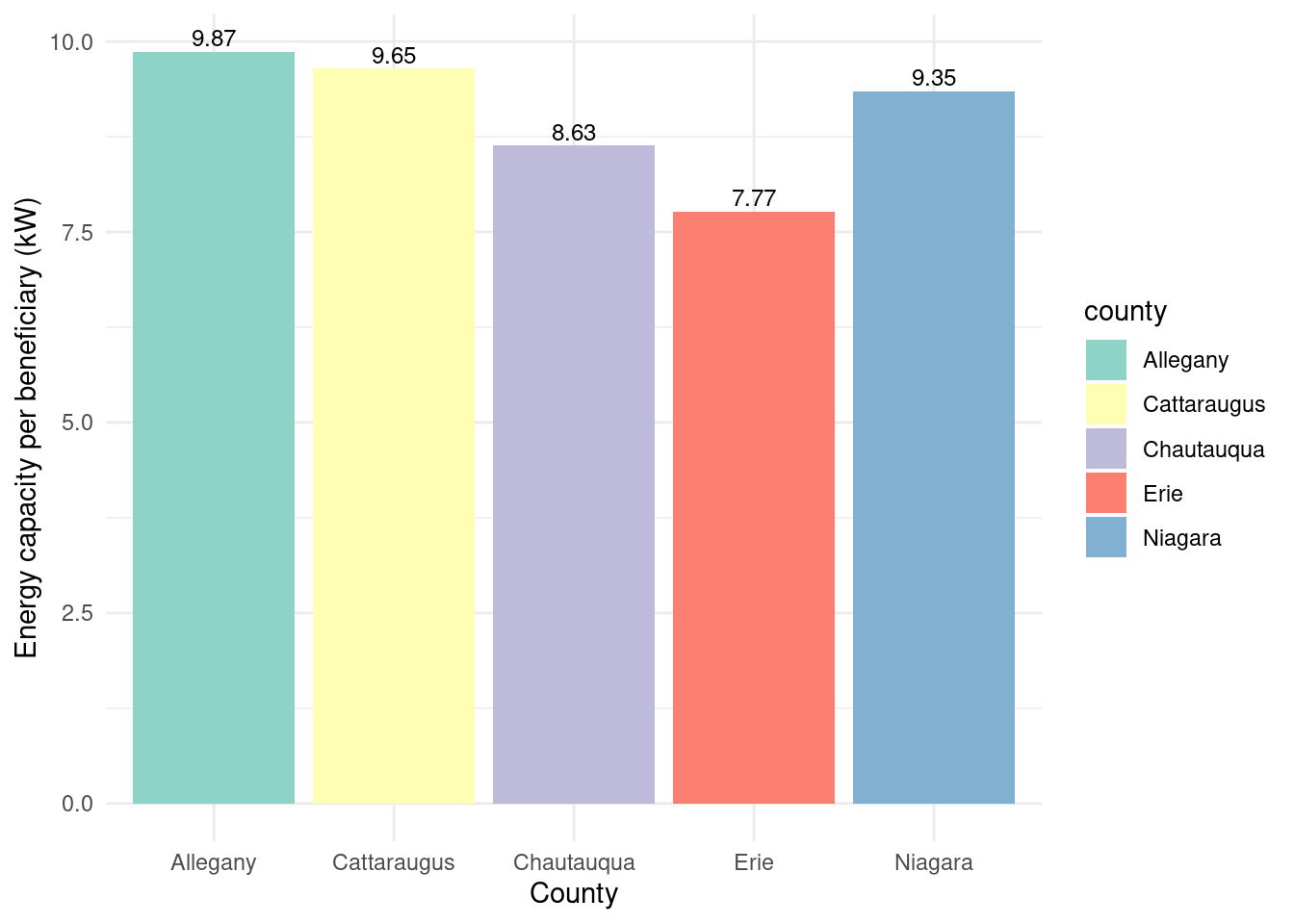
Looks like per project the amount of kw in energy capacity generated was:
In [104]:
# add incentives per beneficiary and rename df to county_projectstats_bybeneficiary_nysun_res_wny? county_avgcap_nysun_res_wny <- county_projectstats_nysun_resi_wny |>mutate(avg_energy_capacity = total_energy_capacity / total_projects,avg_energy_generation = total_energy_generation / total_projects,avg_incentives = total_incentives / total_projects)
Interestingly, the order here now reverses. is this expected? ^Potential question for further analysis - maybe counties with more projects had greater mix of small and large projects?TODO
Graph showing energy capacity and projects by county:
# TODO: what is this graph saying??county_avgcap_nysun_res_wny_long |>ggplot(aes(x = county, y = value, fill = metric)) +geom_bar(stat ="identity", position ="stack") +geom_text(aes(label = value, size =ifelse(metric =="overall_projects", 3, 3)), position =position_stack(vjust =0.5), color ="white") +scale_size_identity() +scale_fill_manual(values =c("total_projects"="red", "total_energy_capacity"="blue"),labels =c("total_projects"="Projects", "total_energy_capacity"="Energy Capacity")) +labs(title ="NY Sun Residential Projects and Energy Capacity by County", x ="County", y ="Val") +theme_minimal()
In [107]:
county_avgcap_nysun_res_wny |>ggplot(aes(x =reorder(county, avg_energy_capacity),y = avg_energy_capacity)) +geom_bar(stat ="identity", fill ="skyblue") +geom_text(aes(label = scales::comma(avg_energy_capacity)), vjust =-0.5, color ="black", size =3.5) +labs(title ="NY Sun Residential Energy Capacity per Project by County", x ="County", y ="Energy Capacity per Project (kW)") +theme_minimal()
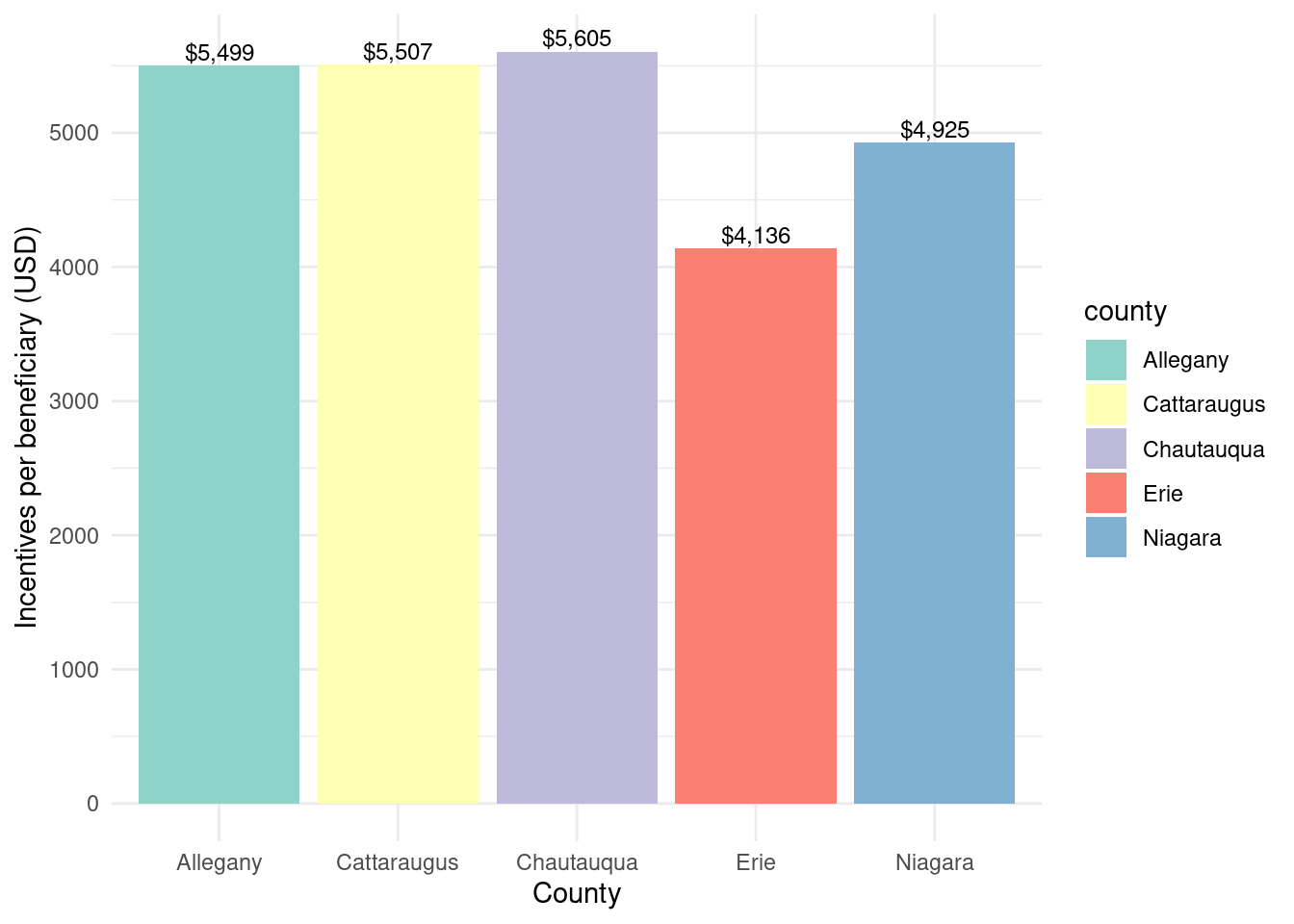
What percent of potential beneficiaries benefitted (by county)?
Some takeaways are: Erie once again has the highest # of potencial beneficiaries (probably due to its sheer size) and it also has the highest amount of incentives. Niagara comes 2nd in both again probably due to size/population.
When we look at incentives per beneficiary, the rural counties clearly recieve more money per person. Chataqua county is in the lead, followed by Cattaraugus and Allegany respectively. Erie County, despite getting most of the funding, has the lowest incentives per beneficiary. Is this because projects are more expensive in rural areas? Or was there just more of a focus there?
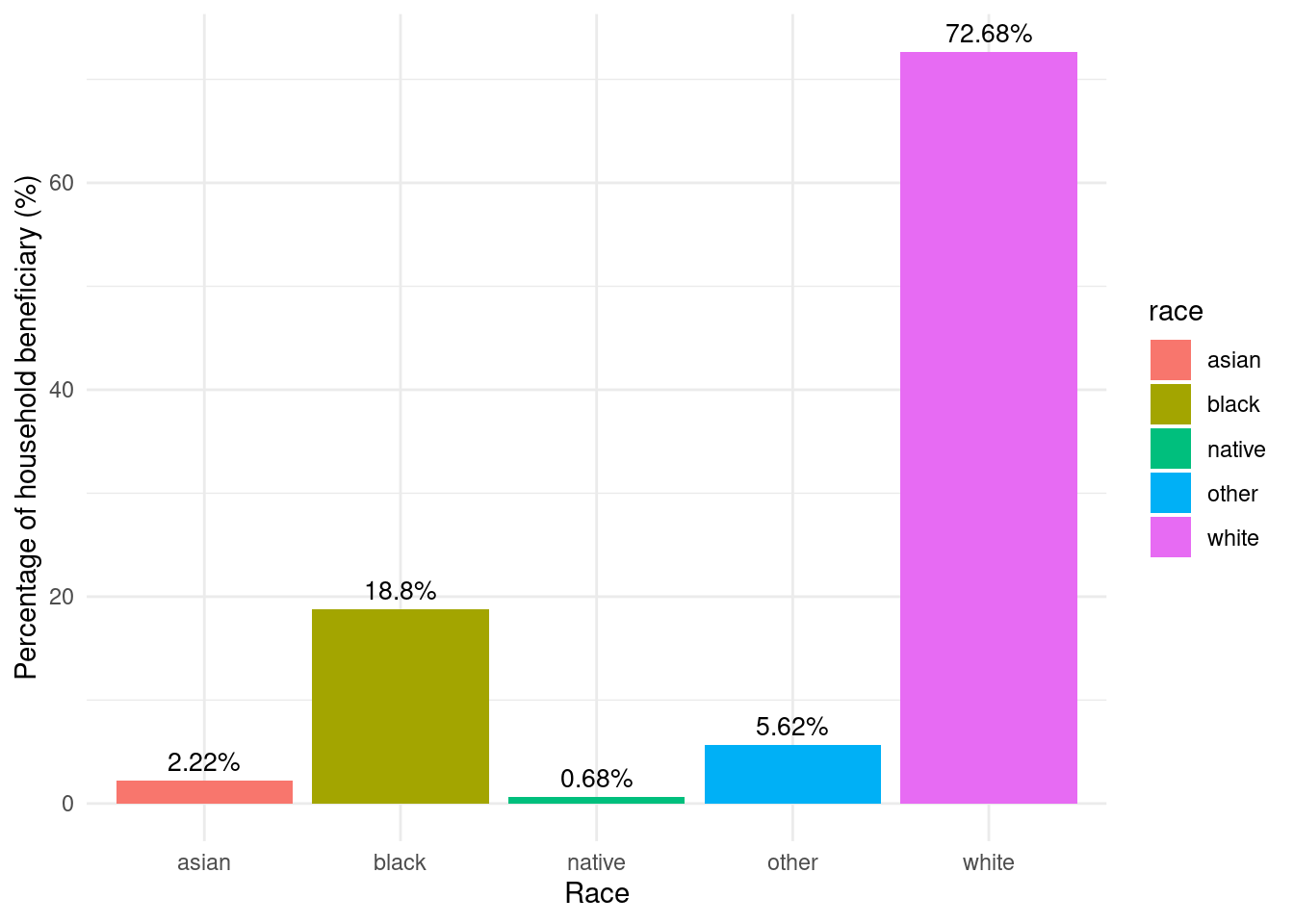
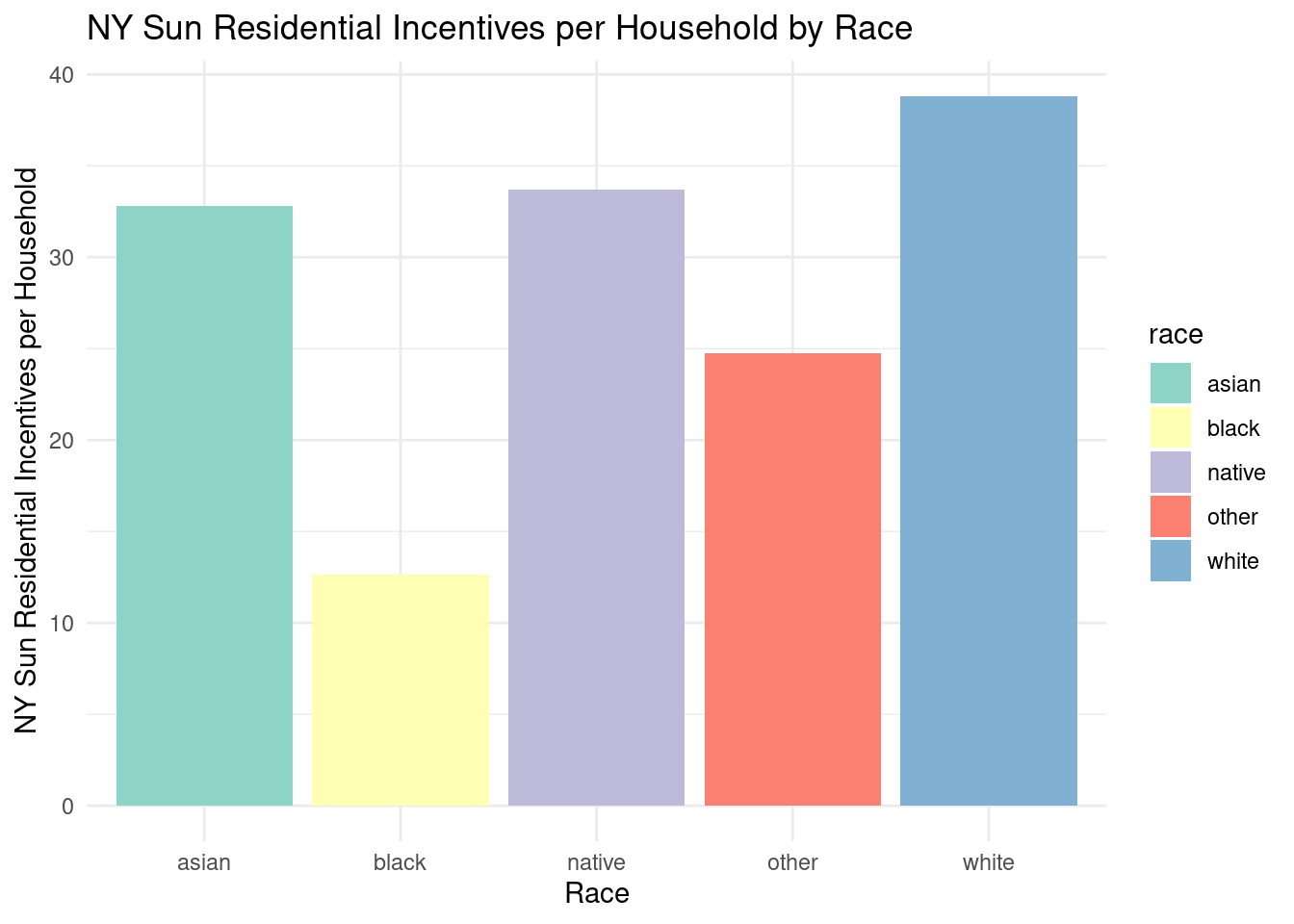
region_totalstats_byrace_nysun_res_wny |>ggplot(aes(x = race, y = incentives_per_hh_by_race, fill = race)) +geom_bar(stat ="identity") +labs(title ="NY Sun Residential Incentives per Household by Race",x ="Race",y ="NY Sun Residential Incentives per Household") +theme_minimal() +scale_fill_brewer(palette ="Set3")
White households received the highest amount of NY Sun Residential incentive per household. Black households received the least amount of Residential incentive per household.
In [122]:
# not region level. double check to see what this doesregion_pctstats_byrace_nysun_res_wny <- county_totalstats_byrace_nysun_res_wny |>mutate(county_nysun_incentive_total =sum(nysun_incentives_race, na.rm =TRUE),county_nysun_totalprojects_race_total =sum(nysun_totalprojects_race, na.rm =TRUE),.by = county ) |>mutate(nysun_incentive_race_county_pct = (nysun_incentives_race / county_nysun_incentive_total) *100,nysun_totalprojects_race_pct = (nysun_totalprojects_race / county_nysun_totalprojects_race_total) *100 )
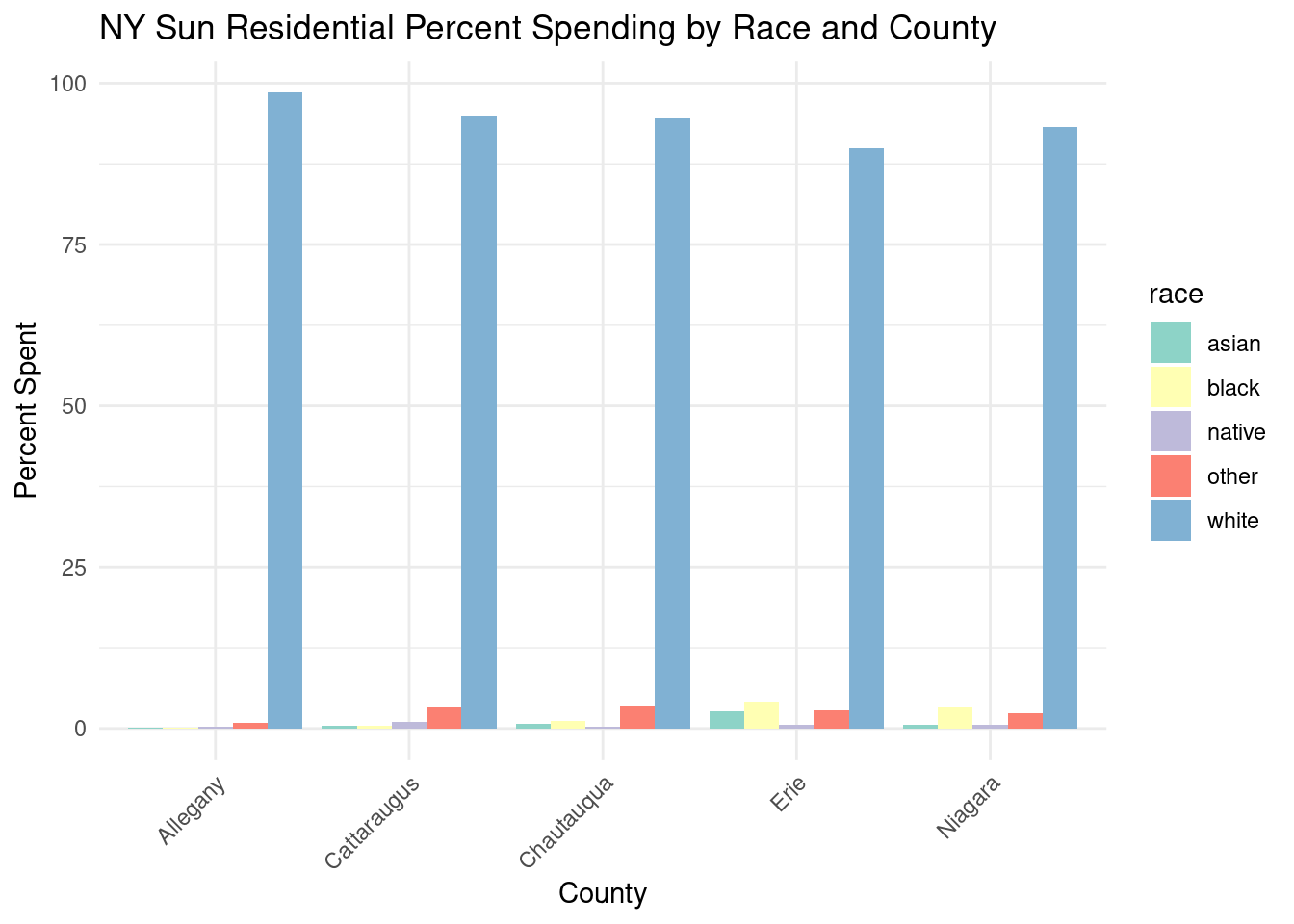
What percent of spending went to white vs. black vs. native vs. other?
By county the percent of spending went to:
1 Allegany white 98.5
2 Allegany black 0.170 3 Allegany native 0.330 4 Allegany asian 0.147 5 Allegany other 0.813
6 Erie white 89.9
7 Erie black 4.16 8 Erie native 0.536 9 Erie asian 2.62 10 Erie other 2.80
11 Cattaraugus white 94.9
12 Cattaraugus black 0.454 13 Cattaraugus native 0.999 14 Cattaraugus asian 0.360 15 Cattaraugus other 3.32
16 Niagara white 93.2
17 Niagara black 3.22 18 Niagara native 0.559 19 Niagara asian 0.583 20 Niagara other 2.41
21 Chautauqua white 94.5
22 Chautauqua black 1.12 23 Chautauqua native 0.335 24 Chautauqua asian 0.688 25 Chautauqua other 3.36
Graph showing the info above:
In [124]:
region_pctstats_byrace_nysun_res_wny |>ggplot(aes(x = county, y = nysun_incentive_race_county_pct, fill = race)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="NY Sun Residential Percent Spending by Race and County",x ="County", y ="Percent Spent") +theme_minimal() +scale_fill_brewer(palette ="Set3") +theme(axis.text.x =element_text(angle =45, hjust =1))
NY Sun Small Commercial
The df region_projectstats_nysun_scom_wny was created to show the overall number of projects, incentives, energy capacity, and energy generation in all of WNY.
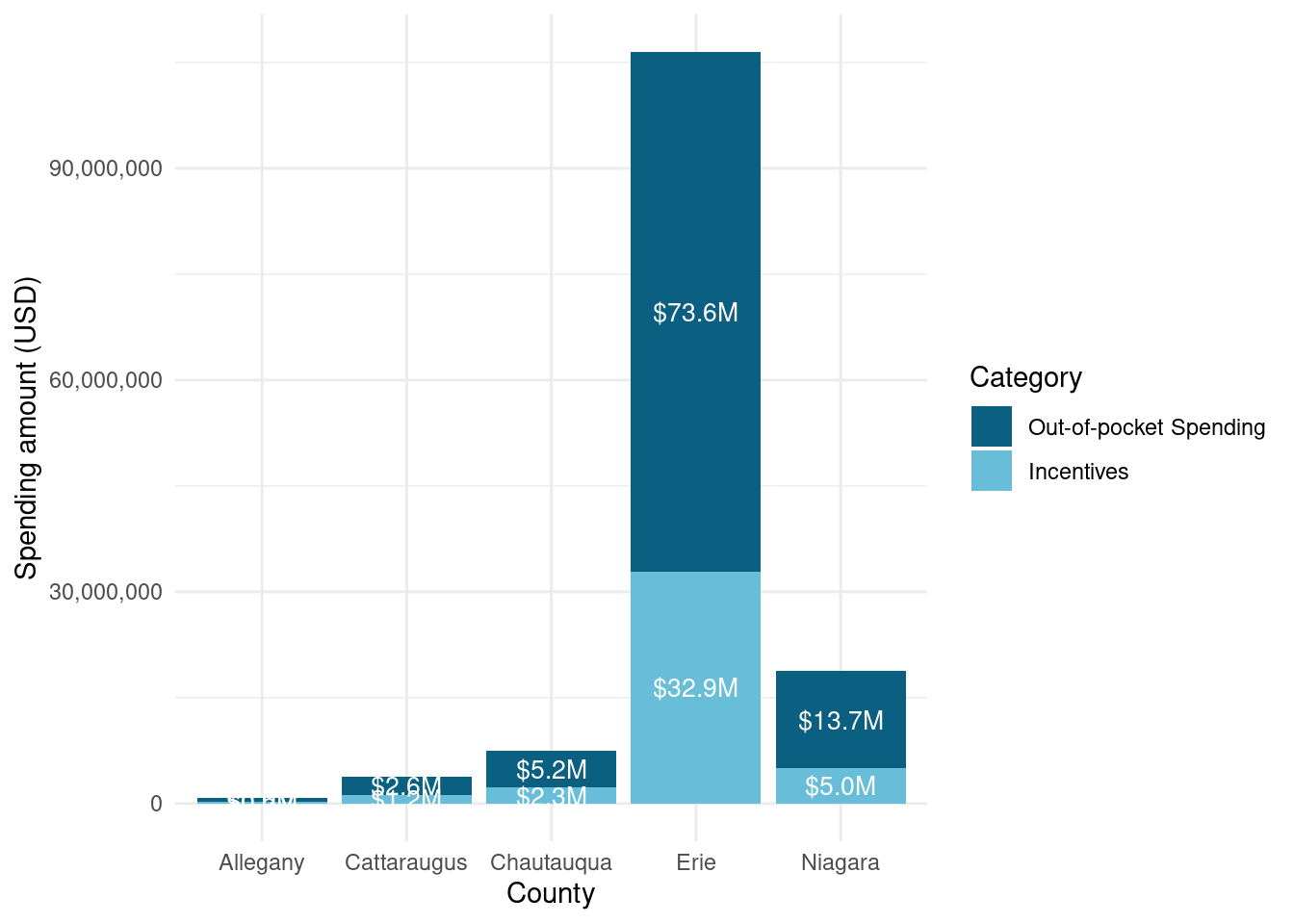
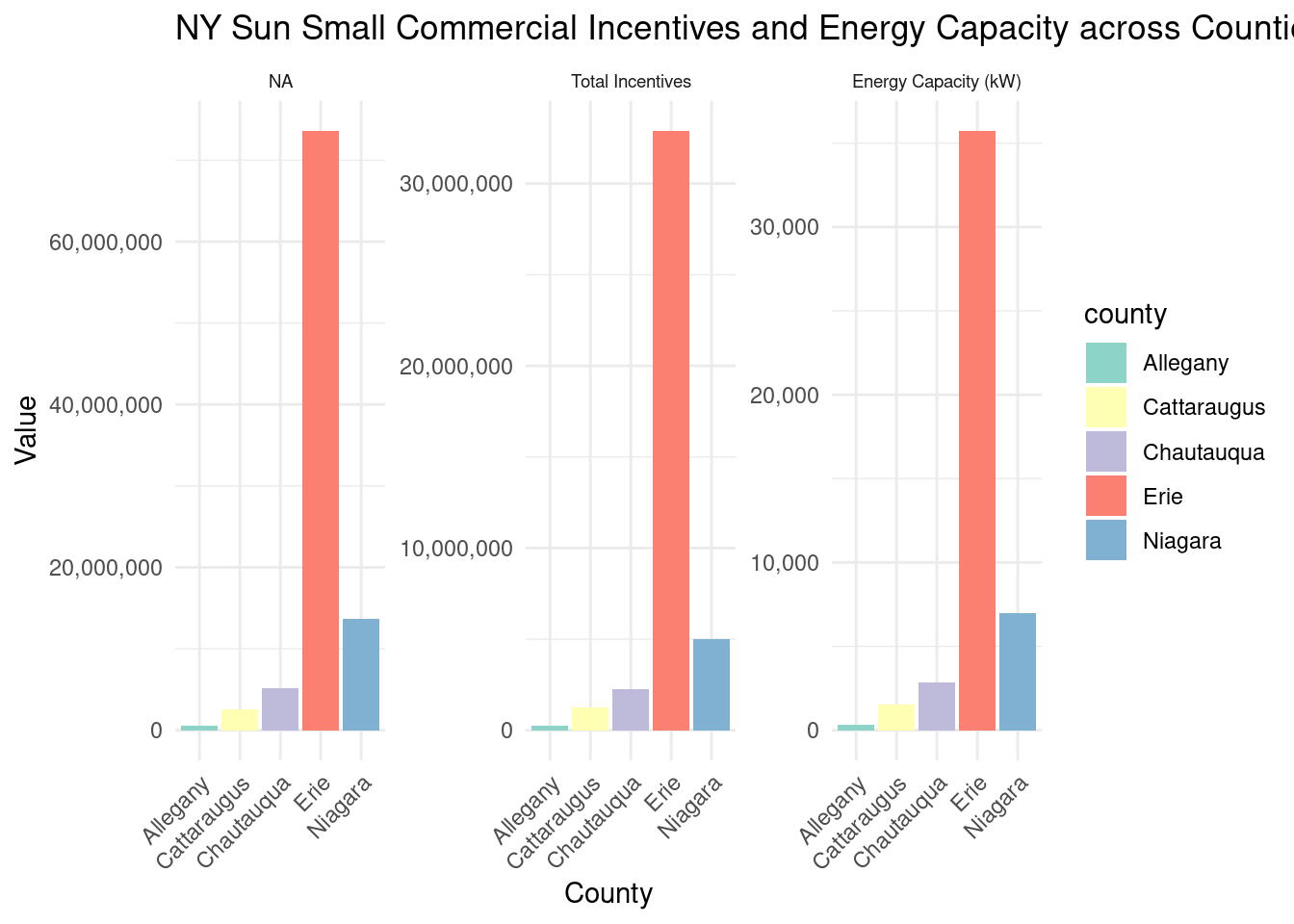
Erie has by far the most money spent for small commercial projects, more than would be expected even given its much larger size than the other counties by population.
What percent of potential beneficiaries benefitted? non applicable to commercial projects.
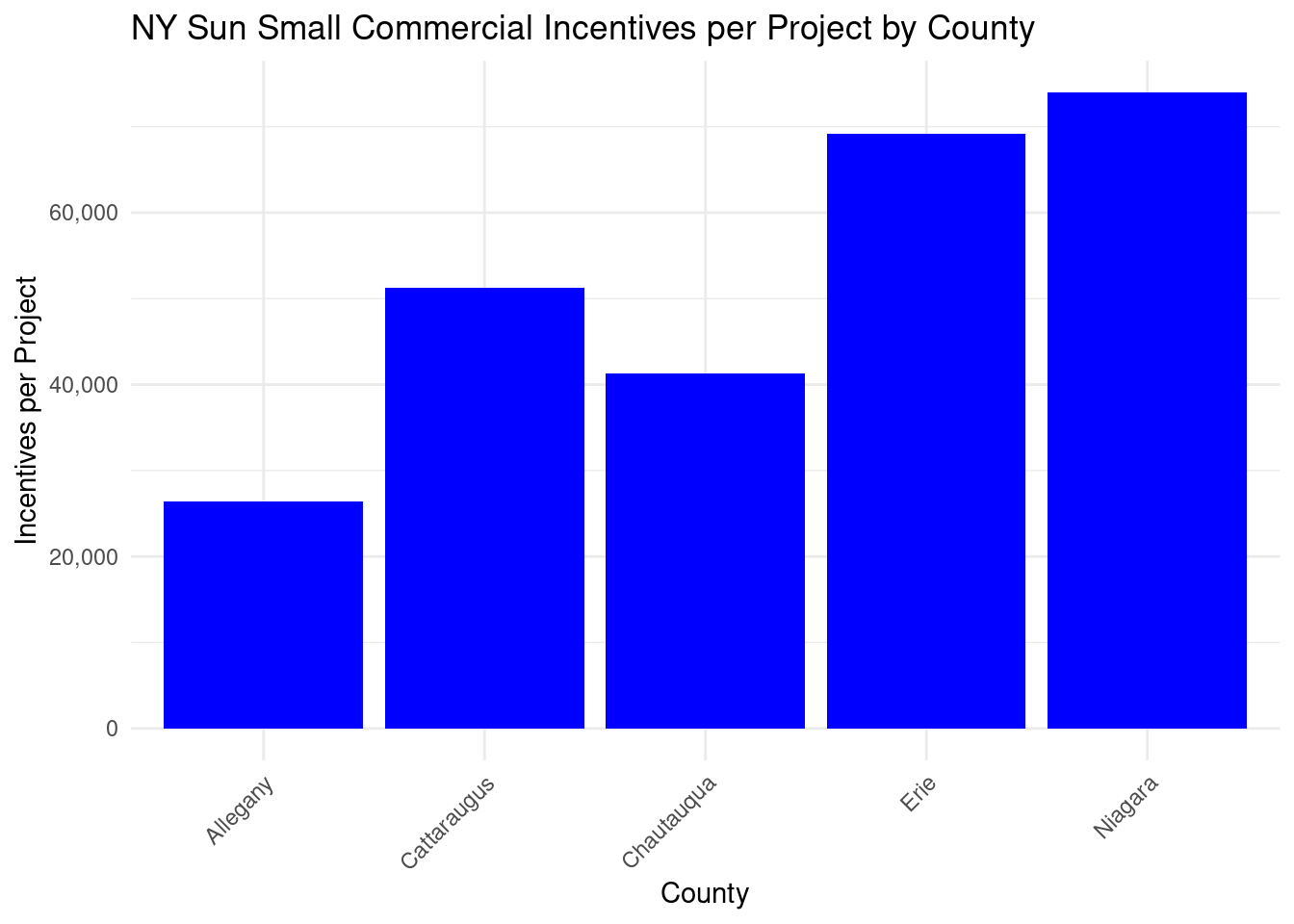
Projects were most expensive in Niagara and Erie counties, with much less spent per project in other counties, particularly in Allegany. It seems that more rural counties had less expensive projects.
Graph showing the above:
In [144]:
county_projectstats_nysun_smallcomm_wny |>mutate(incentives_per_project = total_incentives / total_projects, ) |>distinct(county, incentives_per_project) |>ggplot(aes(x = county, y = incentives_per_project)) +geom_bar(stat ="identity", fill ="blue") +labs(title ="NY Sun Small Commercial Incentives per Project by County",x ="County",y ="Incentives per Project" ) +theme_minimal() +scale_y_continuous(labels = scales::comma) +theme(axis.text.x =element_text(angle =45, hjust =1))
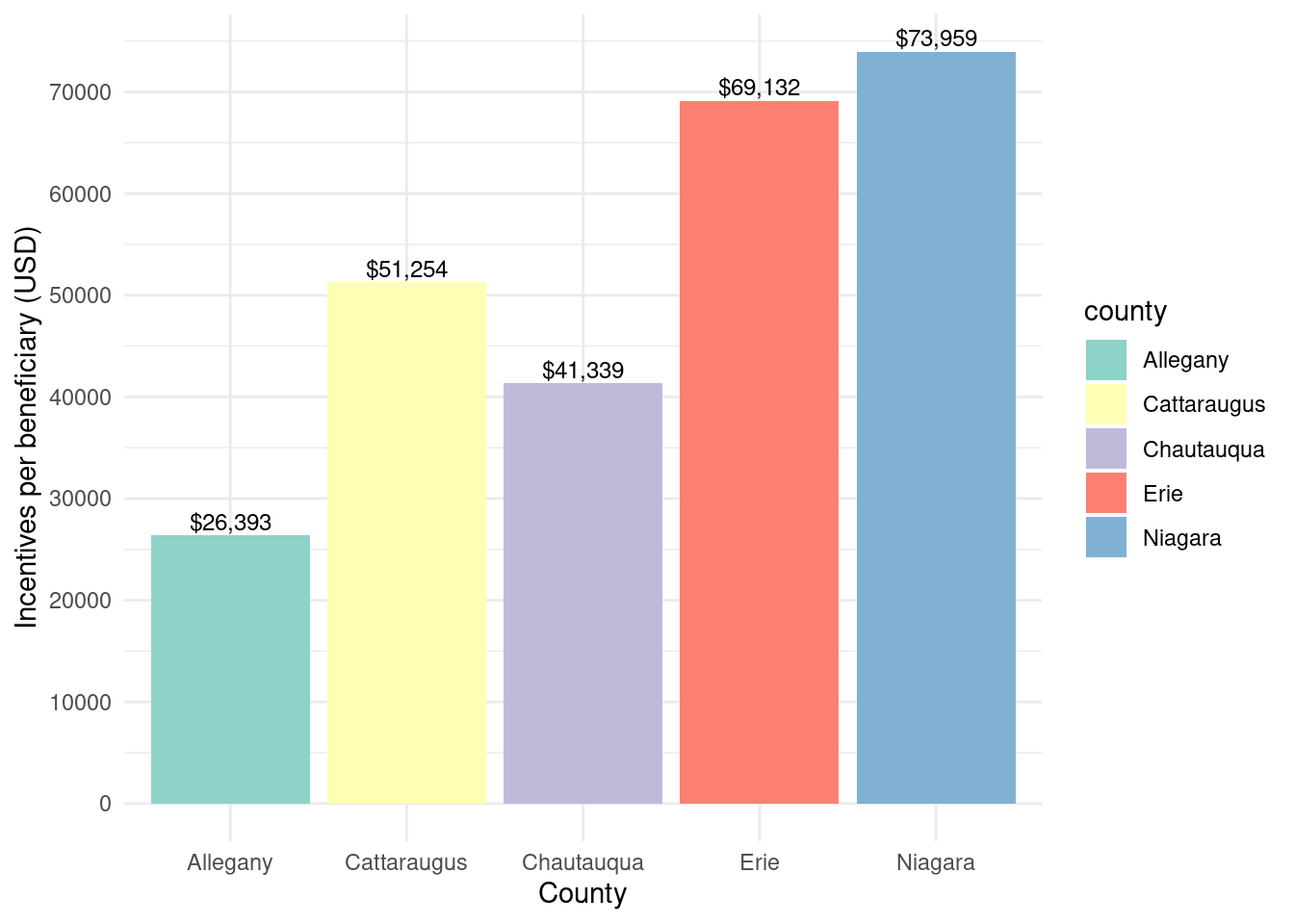
In [145]:
county_totalstats_nysun_smallcomm_wny |>ggplot(aes(x = county, y = incentives_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Incentives per beneficiary (USD)") +geom_text(aes(label =paste0("$", scales::comma(incentives_per_beneficiary, accuracy =1))),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3") +scale_y_continuous(breaks =seq(0, 100000, 10000))
Total incentives per beneficiary by county for NY-Sun Small Commercial program
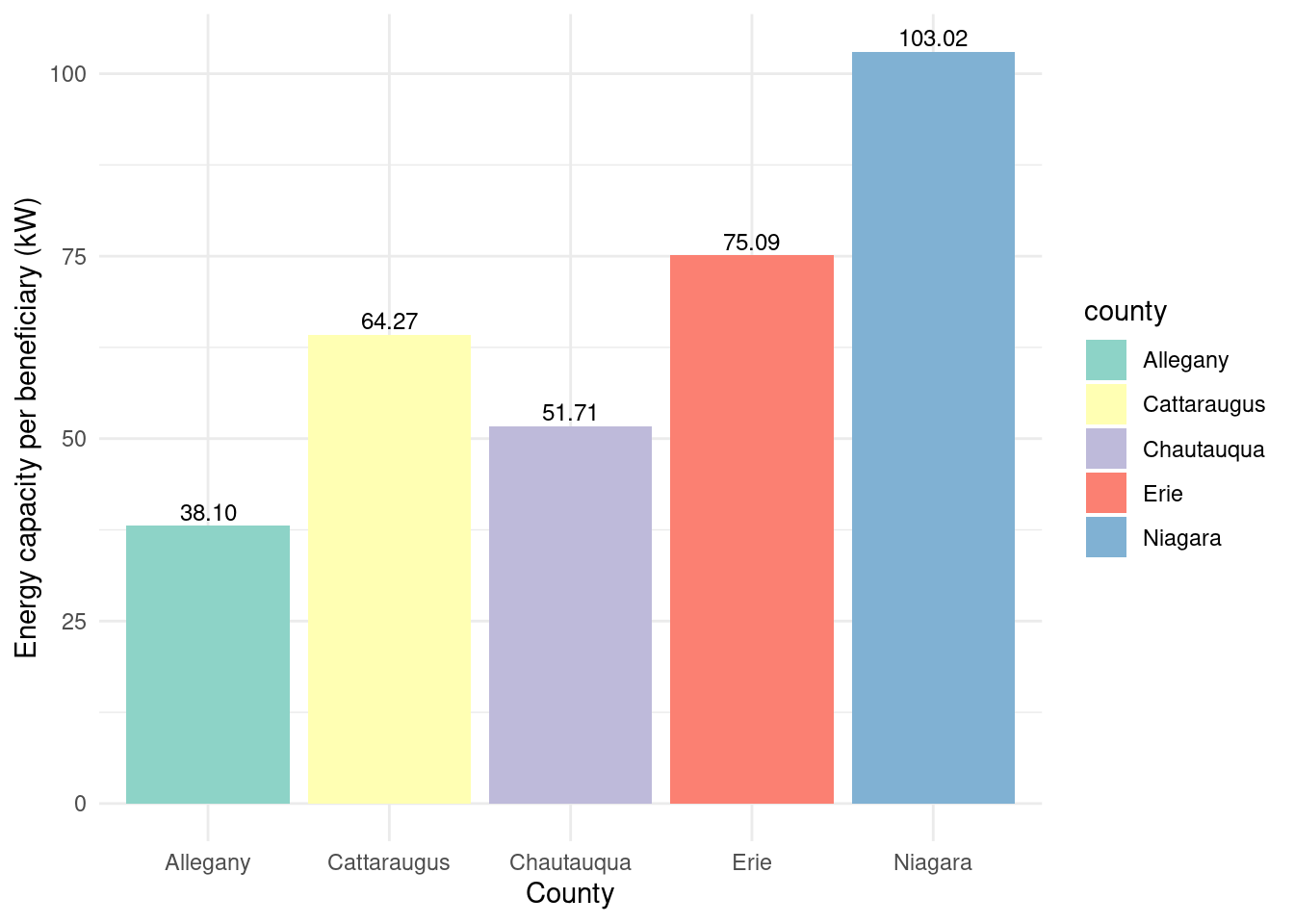
In [146]:
county_totalstats_nysun_smallcomm_wny |>ggplot(aes(x = county, y = energycap_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Energy capacity per beneficiary (kW)") +geom_text(aes(label = scales::comma(energycap_per_beneficiary, accuracy =0.01)),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3")
Energy capacity per installed system by county for NY-Sun Small Commercial program
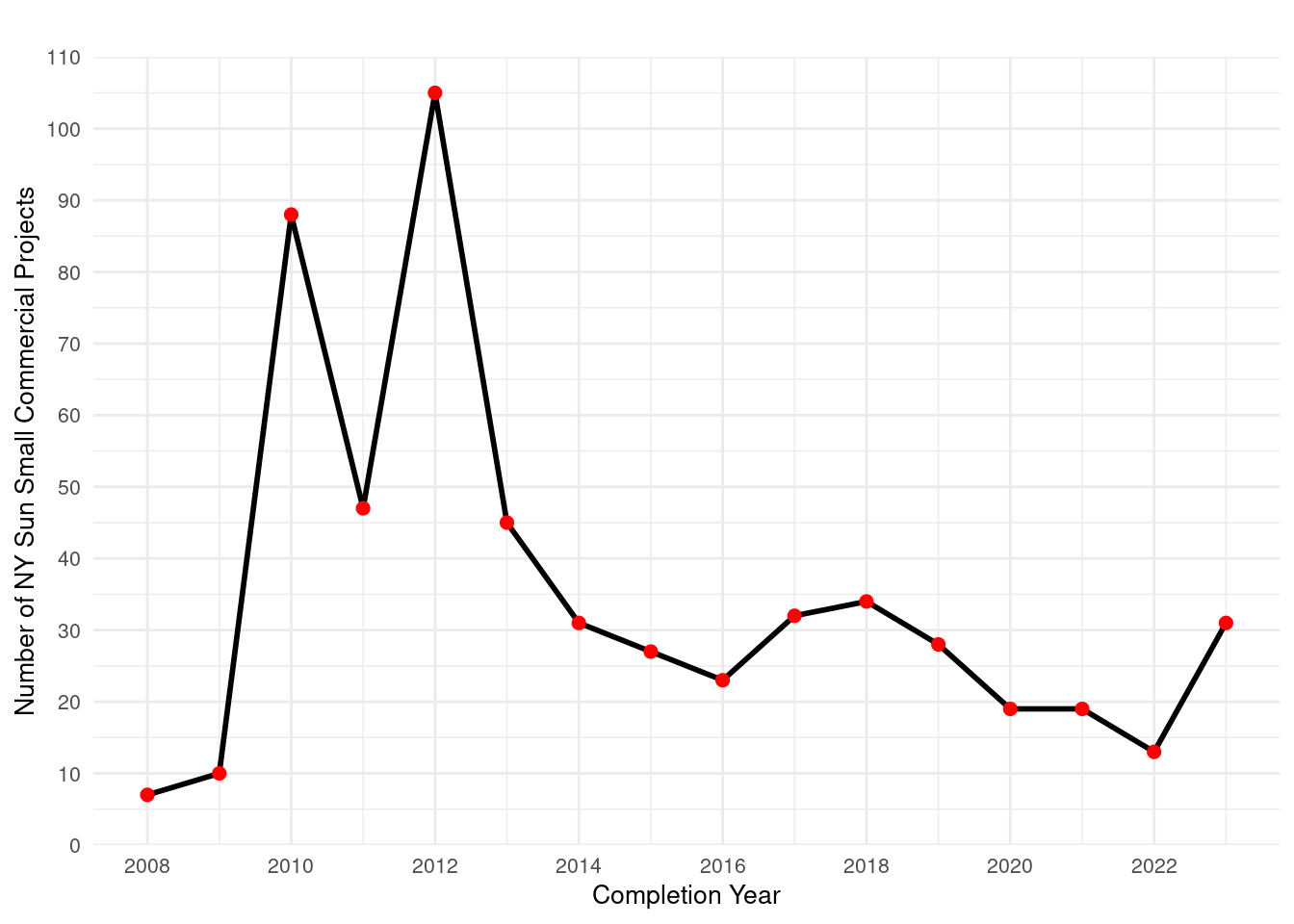
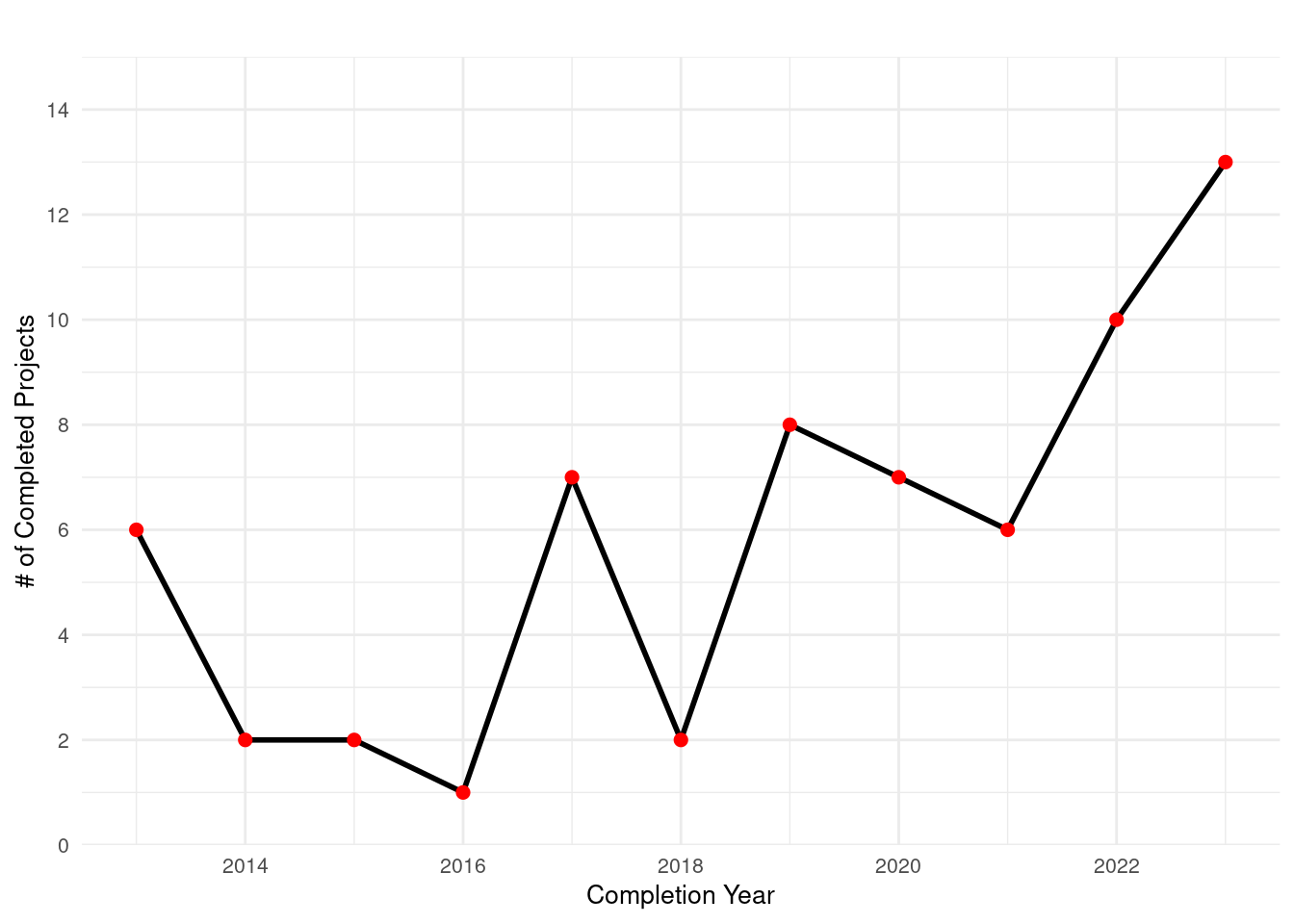
Some of the projects have not yet been completed which is why those have been filtered out.
In [159]:
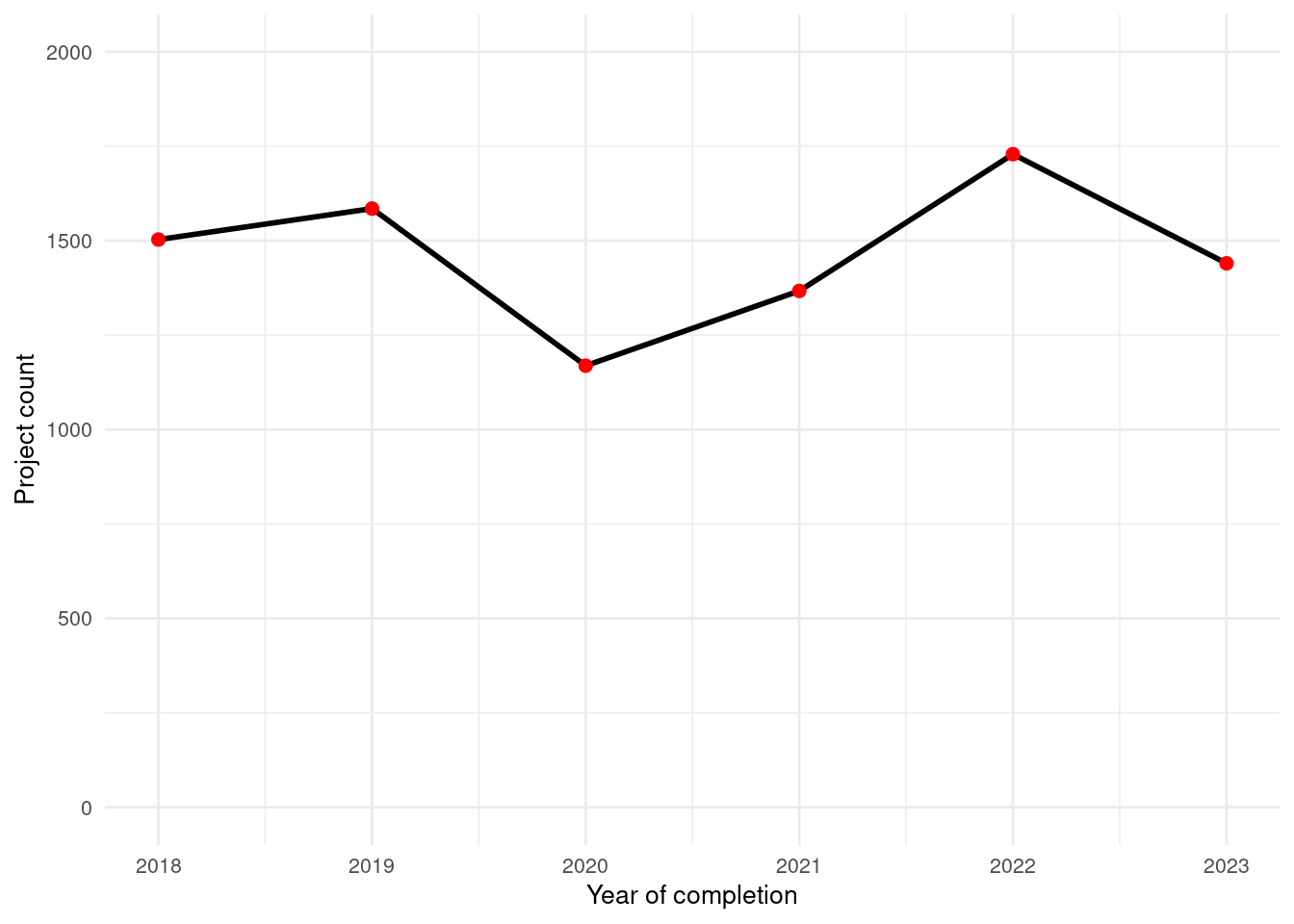
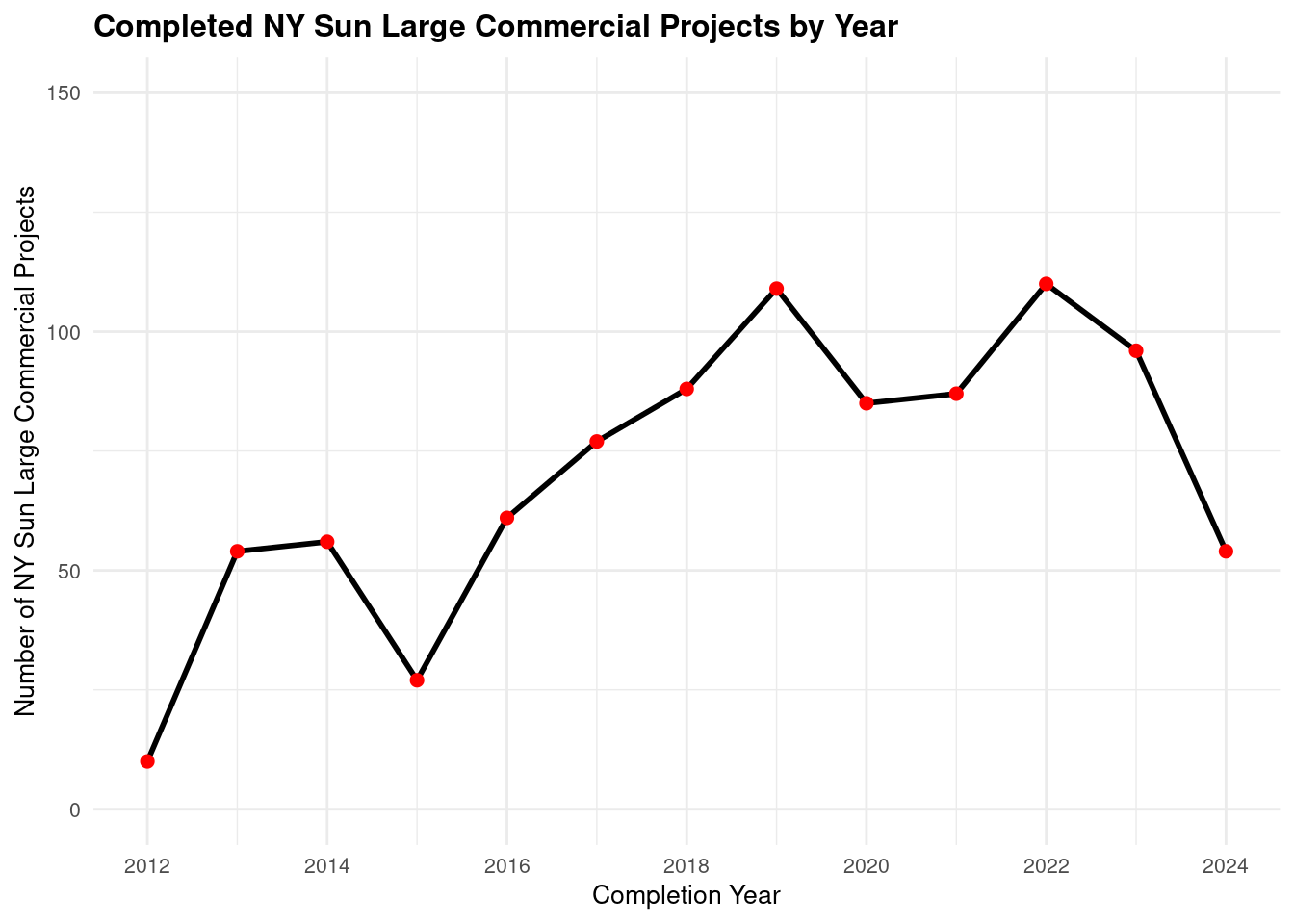
projects_nysun_large_yr |>ggplot(aes(x = completion_year, y = project_count_by_year, group =1)) +geom_line(color ="black", linewidth =1) +geom_point(color ="red", size =2) +labs(title ="Completed NY Sun Large Commercial Projects by Year",x ="Completion Year",y ="Number of NY Sun Large Commercial Projects" ) +scale_x_continuous(breaks =seq(min(projects_nysun_large_yr$completion_year), max(projects_nysun_large_yr$completion_year), by =2)) +scale_y_continuous(breaks =seq(0, 150, by =50), limits =c(0, 150)) +theme_minimal() +theme(plot.title =element_text(size =12, face ="bold"),axis.title =element_text(size =10),axis.text =element_text(size =8),plot.caption =element_text(size =8, hjust =1) )
As with NY Sun small commercial, not much of a decrease in 2020, whereas Assisted and Empower had significant drops in number of projects per year in 2020. It could be that commercial projects did not experience a decrease in number during the pandemic, while household projects were more affected.
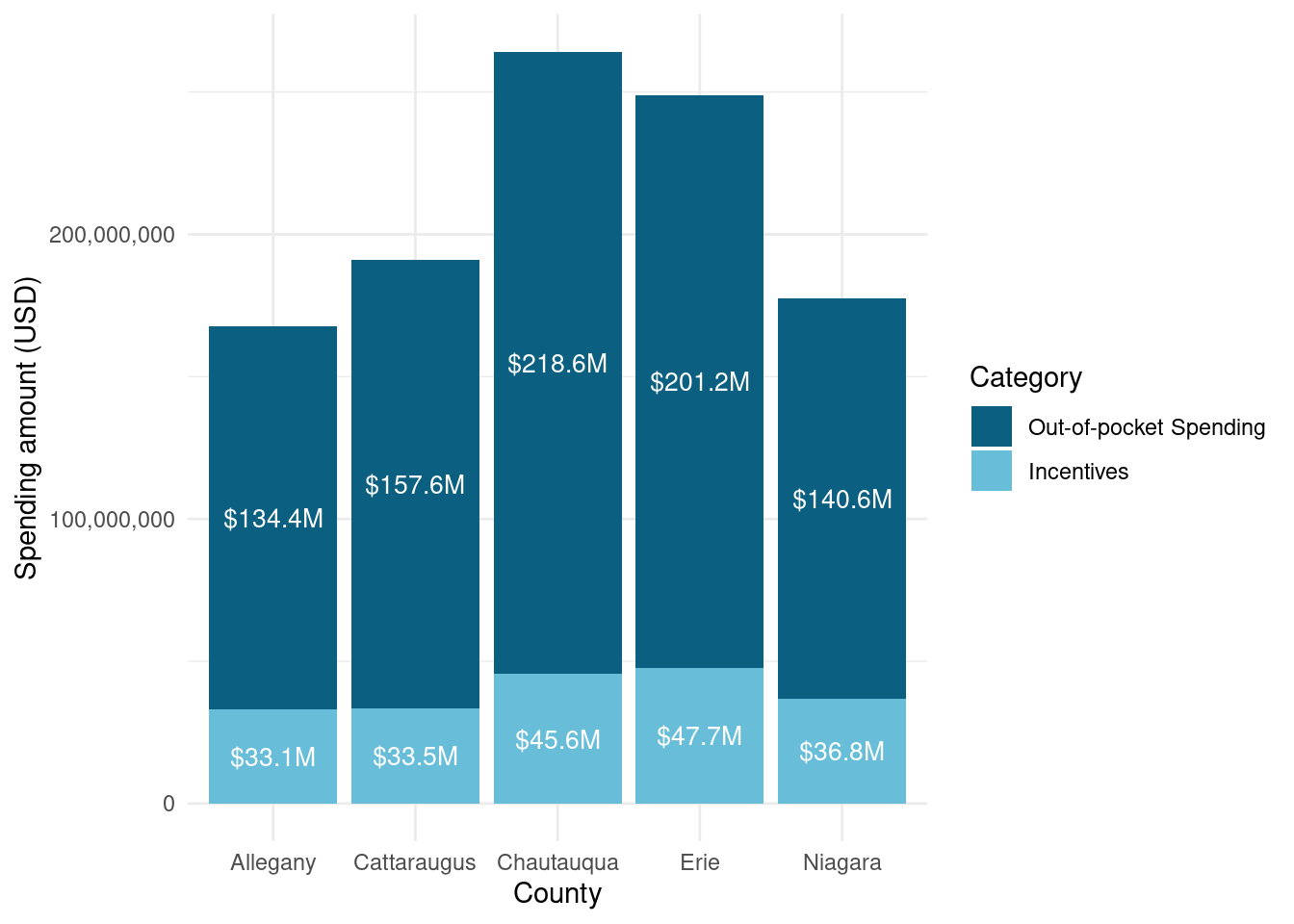
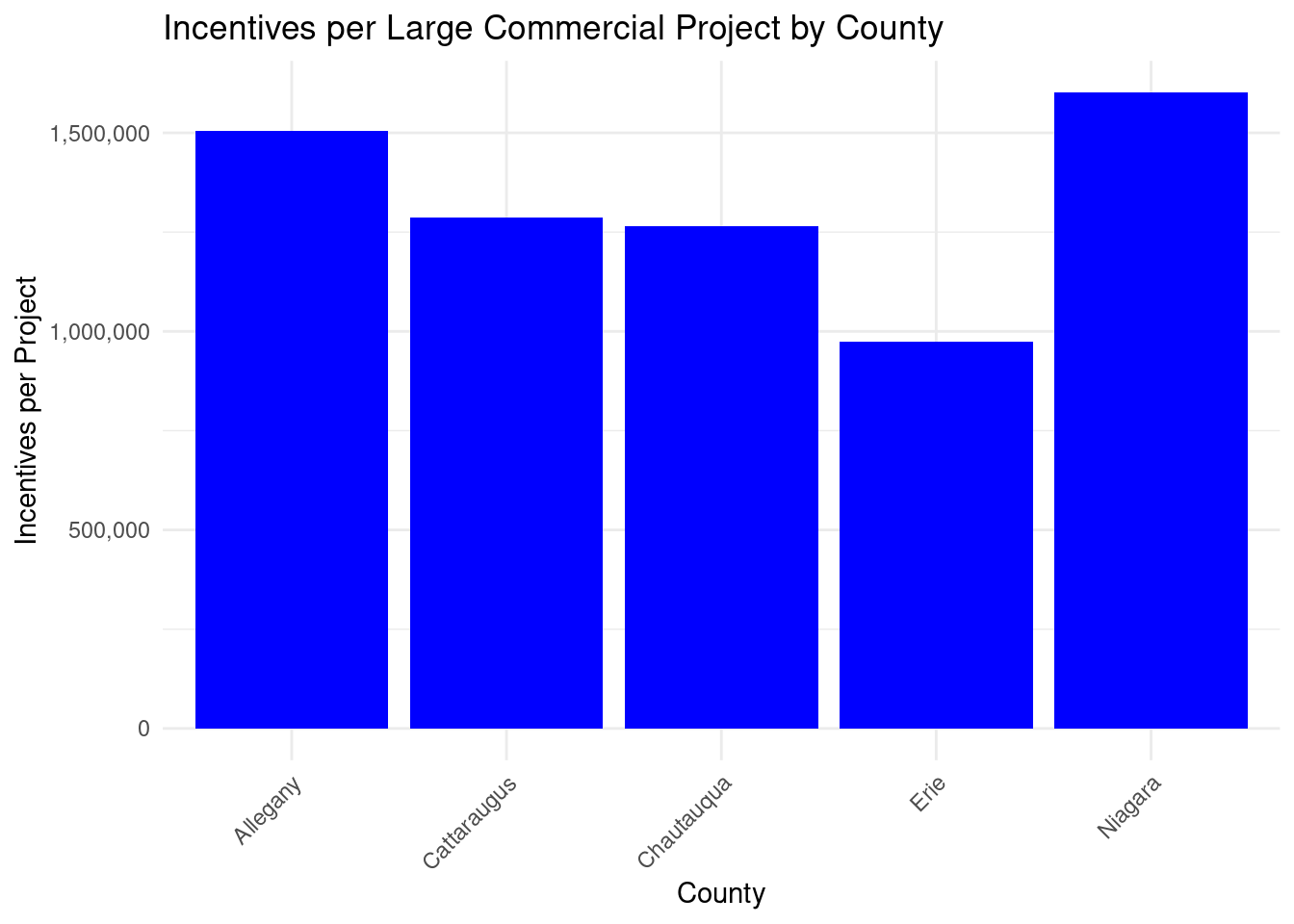
The range of incentives per county is fairly low. Erie and Chautauqua had similar amounts of spending per county, and Allegany had only about 30% less spending than Erie. This is surprising given how much bigger population is in Erie, however counties had small numbers of large commercial projects overall (for example, only 49 projects in Erie).
What percent of potential beneficiaries benefitted? Cannot be calculated for commercial projects as we have hh info only.
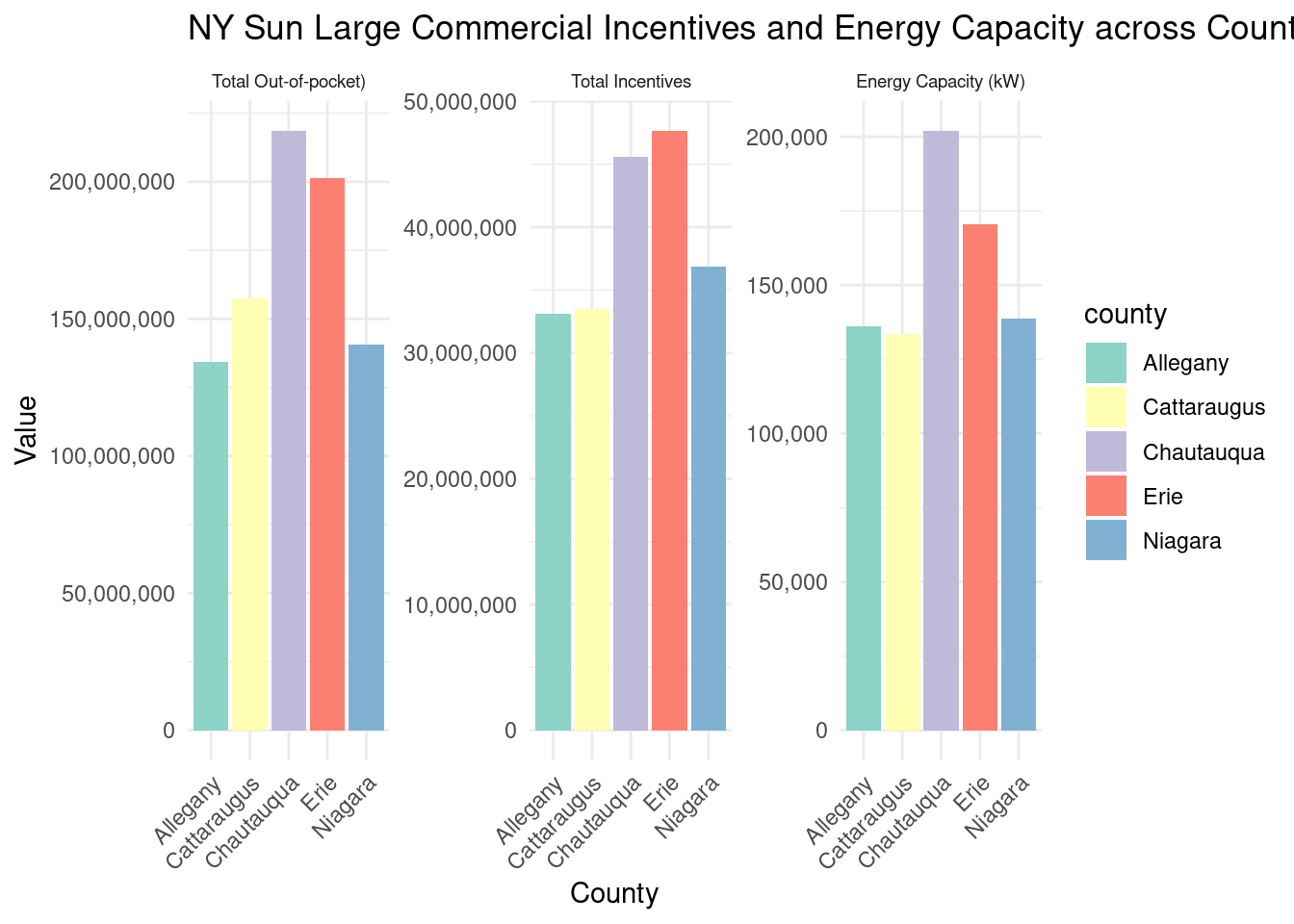
How much energy capacity? (kw) By county in desc order:
county_projectstats_nysun_largecomm_wny_long |>ggplot(aes(x = county, y = value, fill = county)) +geom_bar(stat ="identity") +facet_wrap(~category, scales ="free_y", labeller = labels_largecomm) +labs(title ="NY Sun Large Commercial Incentives and Energy Capacity across Counties",x ="County",y ="Value" ) +theme_minimal() +scale_fill_brewer(palette ="Set3") +scale_y_continuous(labels = scales::comma) +theme(axis.text.x =element_text(angle =45, hjust =1),strip.text.x =element_text(size =7) )
While it could be reasonable to assume that more incentives/spending could lead to higher energy capacity, this does not seem to be the case particularly in Erie and Chatauqua. On the other hand, it seems like there might be some correlation in Allegany, Cattaraugus and Niagara.
Could it be that it is more expensive to build in some counties than others, and this is reflected in differing incentive amounts? Clearly there is some external influence affecting the relationship between incentives and energy capacity that we are unable to directly observe. ### Geography
Where are the potential beneficiaries?
By county?
Answering this as large commercial projects per county:
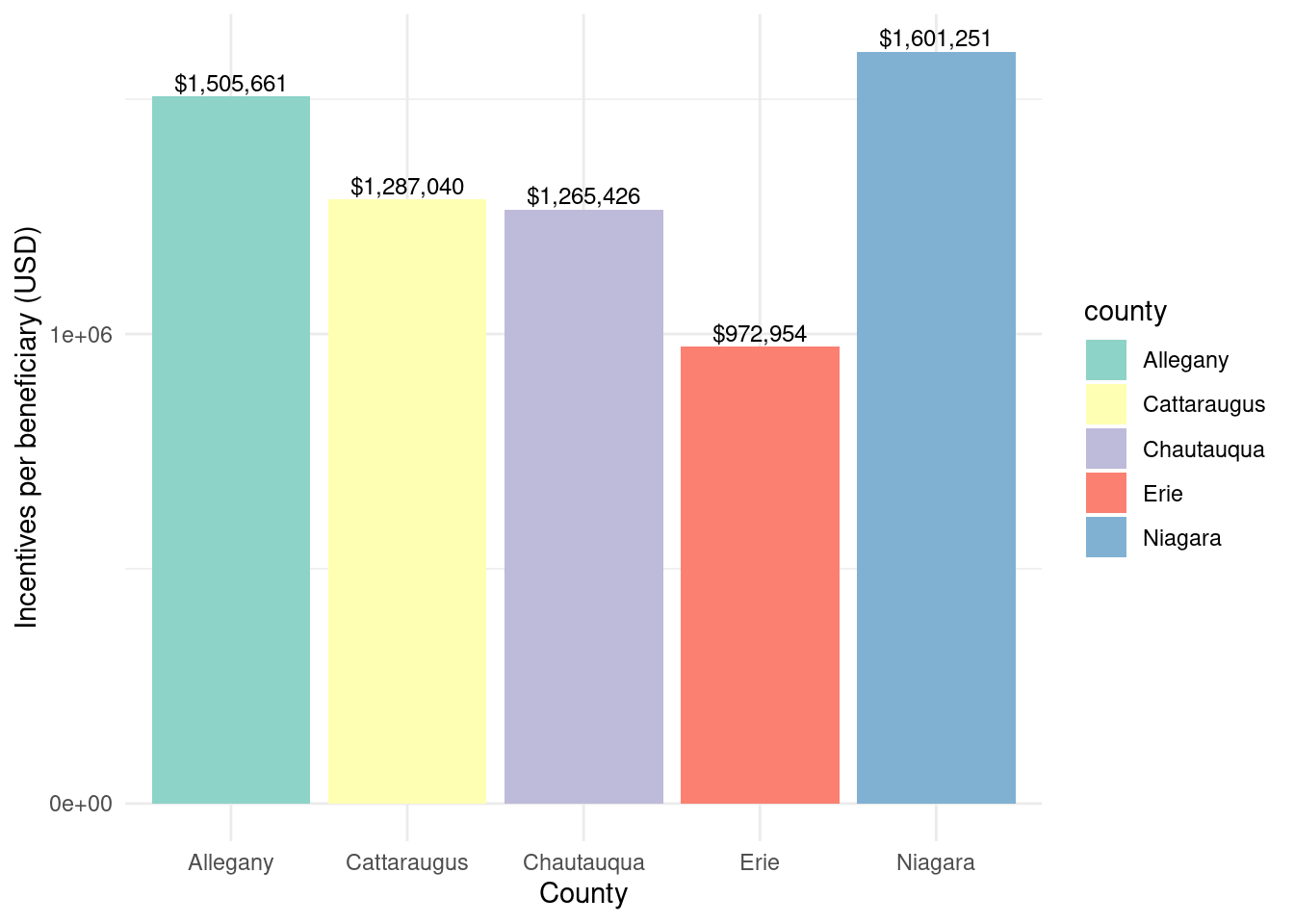
county_totalstats_nysun_largecomm_wny |>ggplot(aes(x = county, y = incentives_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Incentives per beneficiary (USD)") +geom_text(aes(label =paste0("$", scales::comma(incentives_per_beneficiary, accuracy =1))),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3") +scale_y_continuous(breaks =seq(0, 2000000, 1000000))
Total incentives per beneficiary by county for NY-Sun Large Commercial program
In [167]:
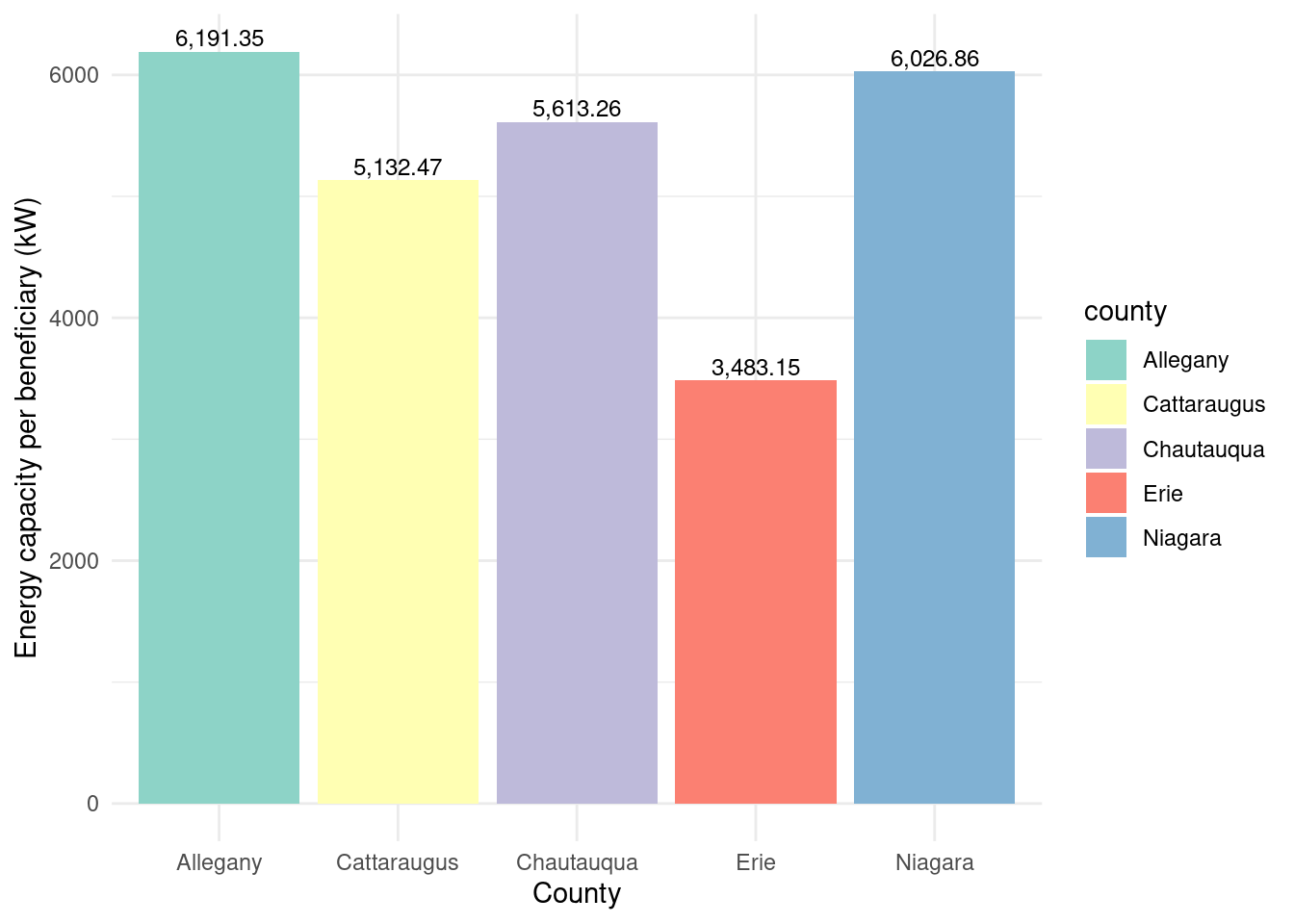
county_totalstats_nysun_largecomm_wny |>ggplot(aes(x = county, y = energycap_per_beneficiary, fill = county)) +geom_bar(stat ="identity") +theme_minimal() +labs(x ="County",y ="Energy capacity per beneficiary (kW)") +geom_text(aes(label = scales::comma(energycap_per_beneficiary, accuracy =0.01)),vjust =-0.3,color ="black",position =position_dodge(width =0.9),size =3.2) +scale_fill_brewer(palette ="Set3")
Energy capacity per installed system by county for NY-Sun Large Commercial program
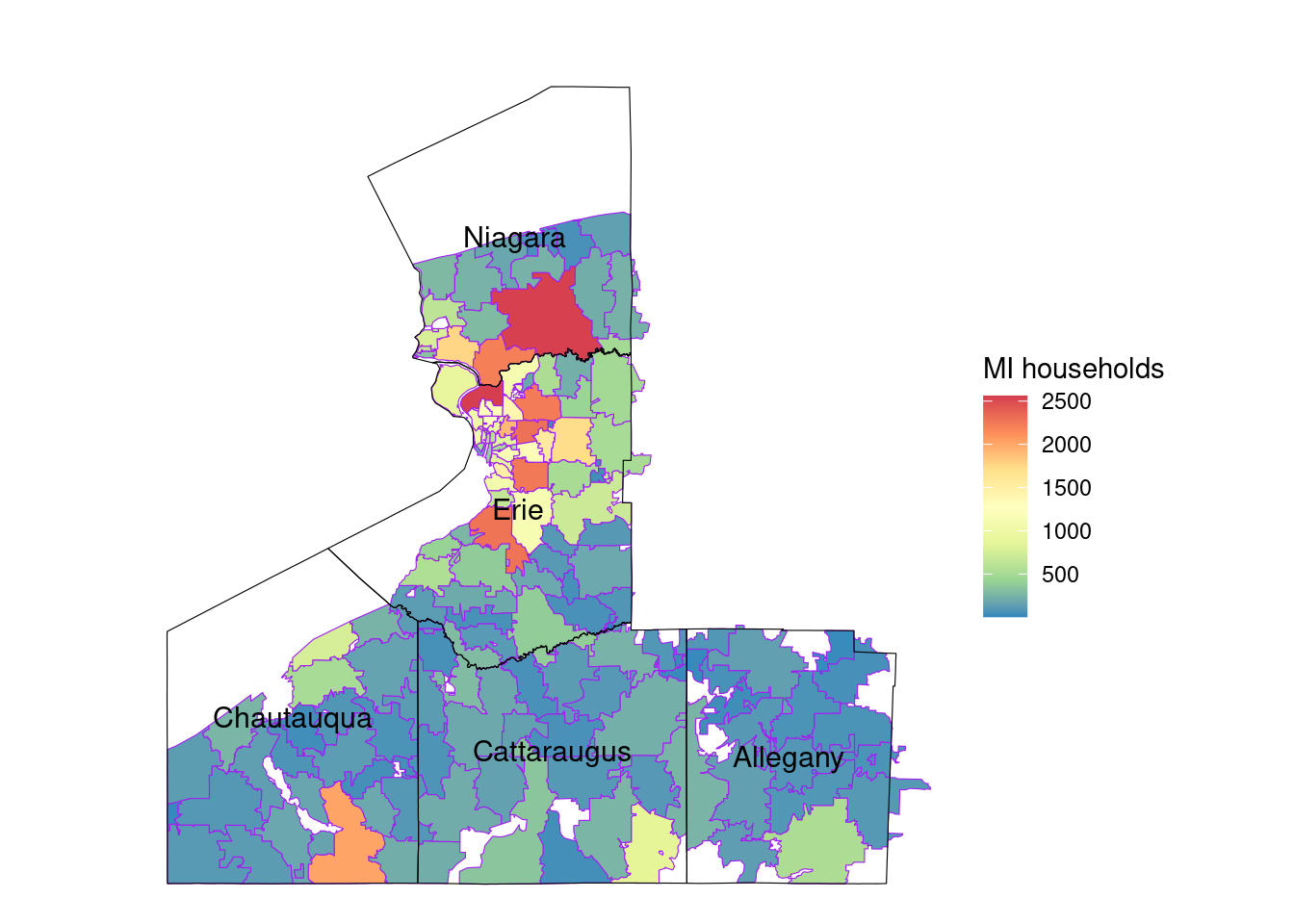
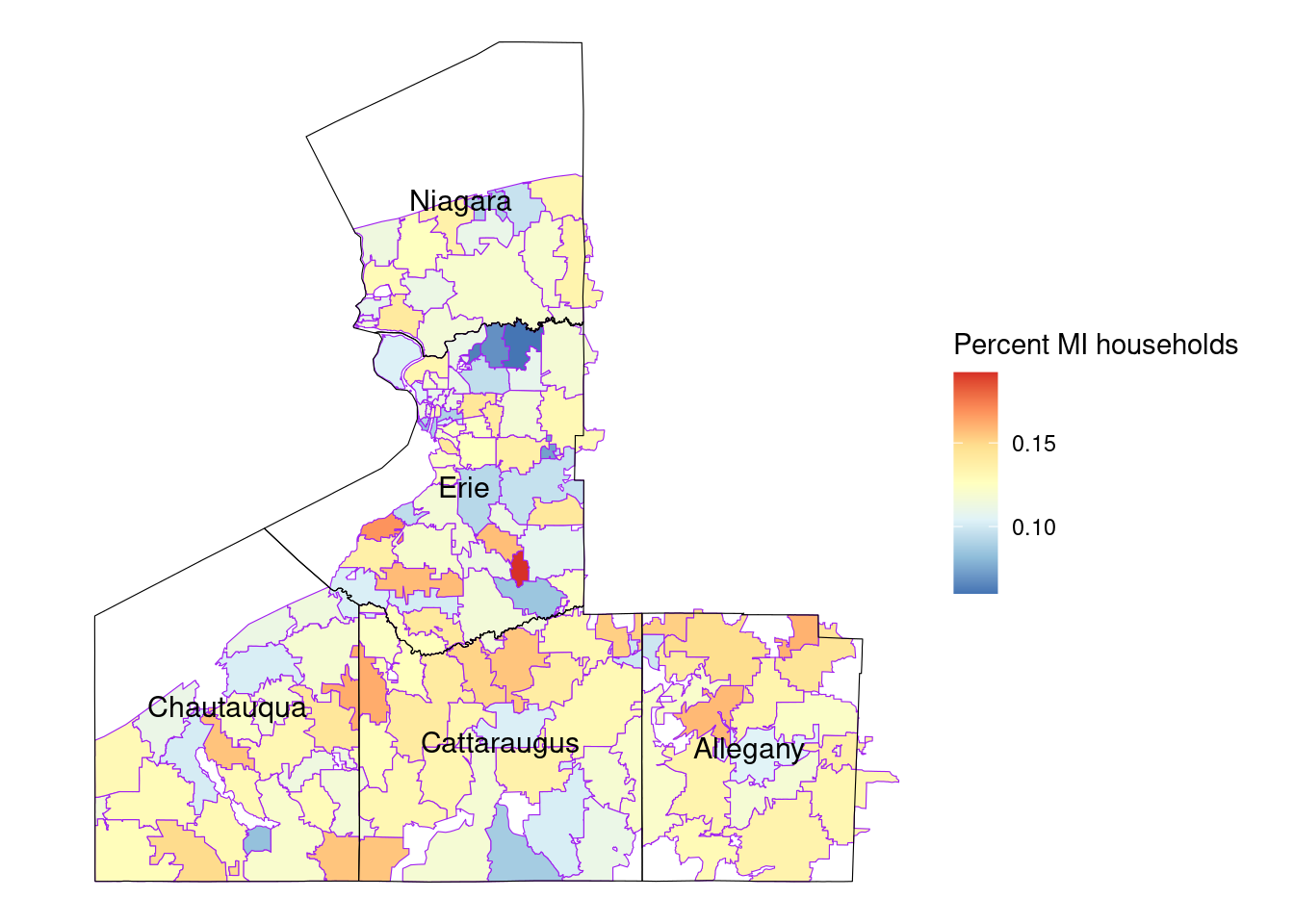
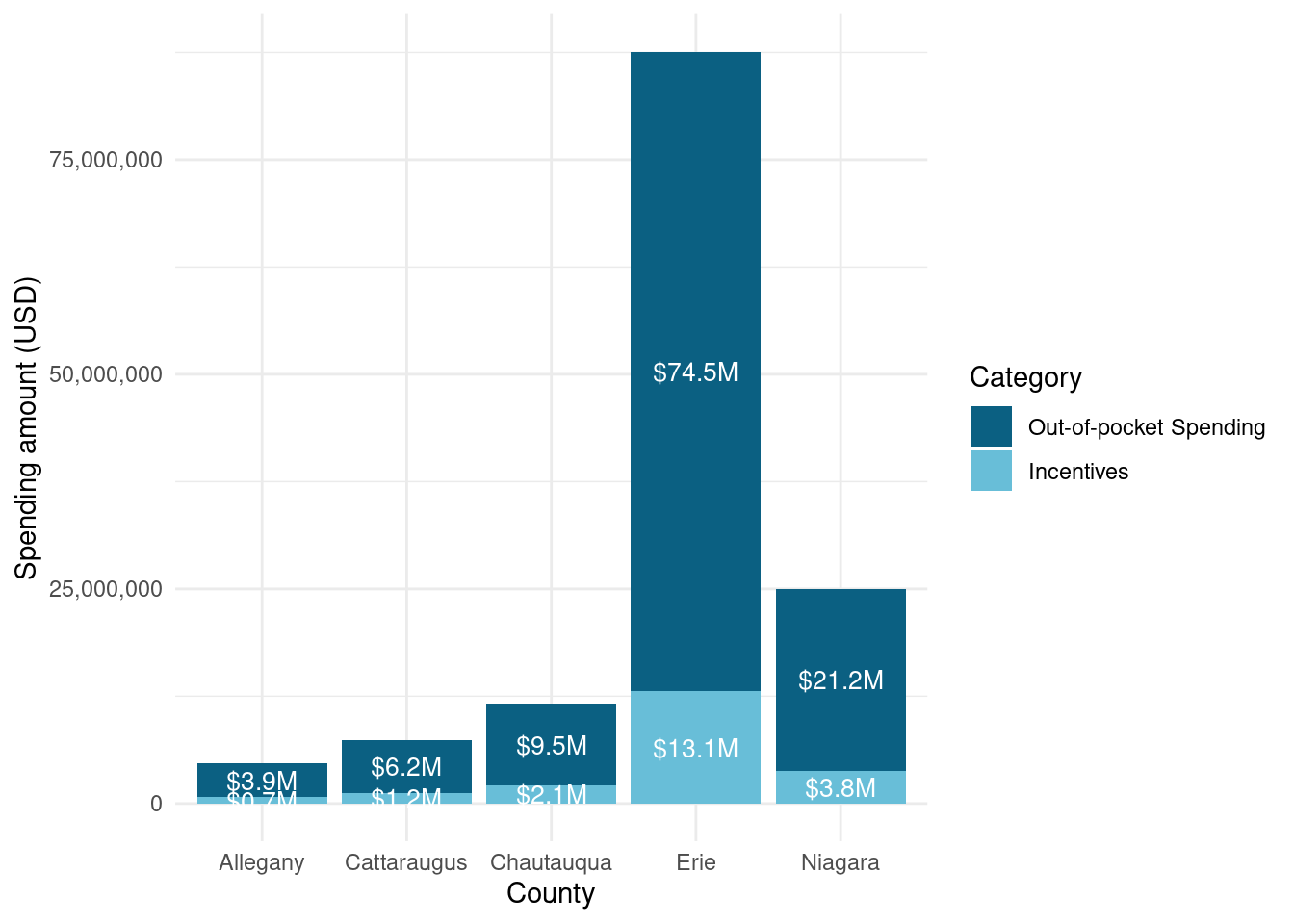
Number of completed Assisted projects by yearIncentives and Out-of-pocket Spending by CountyNumber of moderate income households, by zip codePercent of eligible households for Assisted programAssisted Incentives by Beneficiary vs. Potential BeneficiariesTBDTotal project spending per beneficiary by county for Assisted programBill savings per beneficiary by county for Assisted programEnergy savings per beneficiary by county for Assisted programAssisted program incentives per household by race for WNYRacial makeup of middle income households in WNYRacial makeup of moderate income households in WNYNumber of completed Empower projects by yearIncentives Spending by CountyTBDPercent Empower eligible households (WNY)TBDTotal incentives per beneficiary by county for Empower programBill savings per beneficiary by county for Empower programEnergy savings per beneficiary by county for Empower programTBDRacial makeup of low income households in WNYRacial makeup of Empower program’s beneficiary households in WNYNumber of completed NY Sun Residential projects by yearIncentives and Out-of-pocket Spending by CountyTBDTotal incentives per beneficiary by county for NY-Sun Residential programEnergy capacity per installed system by county for NY-Sun Residential programEnergy generated per installed PV system by county for Empower programRacial makeup of all households in WNYRacial makeup of NY-Sun Residential program’s beneficiary households in WNYCompleted NY Sun small commercial projects by yearIncentives and Out-of-pocket Spending by CountyTotal incentives per beneficiary by county for NY-Sun Small Commercial programEnergy capacity per installed system by county for NY-Sun Small Commercial programCompleted NY Sun small commercial projects by yearIncentives and Out-of-pocket Spending by CountyTotal incentives per beneficiary by county for NY-Sun Large Commercial programEnergy capacity per installed system by county for NY-Sun Large Commercial program